Evaluating the true reasoning capabilities of large language models (LLMs) in coding has long been hampered by benchmarks that are…
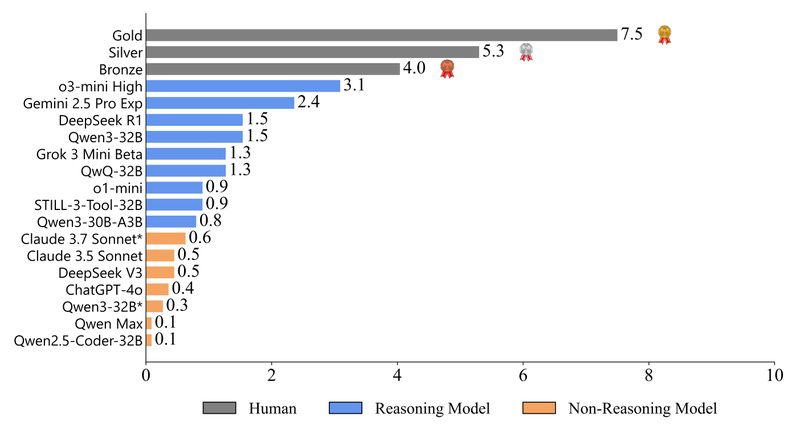
Evaluating the true reasoning capabilities of large language models (LLMs) in coding has long been hampered by benchmarks that are…