Evaluating large vision-language models (LVLMs) used to be a fragmented, time-consuming chore—juggling dozens of benchmark repositories, writing custom data loaders,…
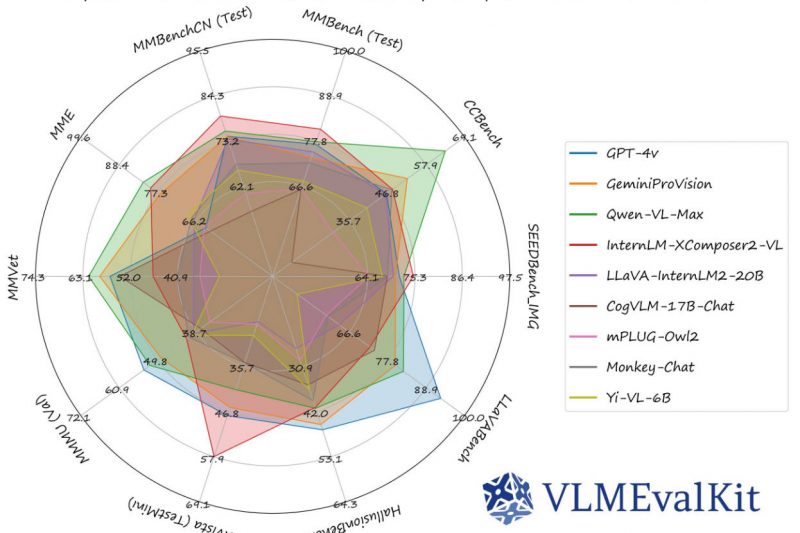
Evaluating large vision-language models (LVLMs) used to be a fragmented, time-consuming chore—juggling dozens of benchmark repositories, writing custom data loaders,…