Generating high-fidelity videos with diffusion models has long been bottlenecked by computational inefficiency. Even on powerful GPUs, producing just a…
Generating high-fidelity videos with diffusion models has long been bottlenecked by computational inefficiency. Even on powerful GPUs, producing just a…

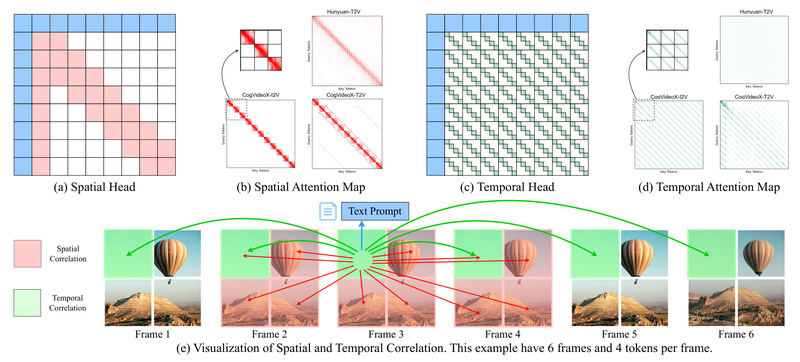
Video generation using diffusion transformers (DiTs) has reached remarkable visual fidelity—but at a steep computational cost. The quadratic complexity of…
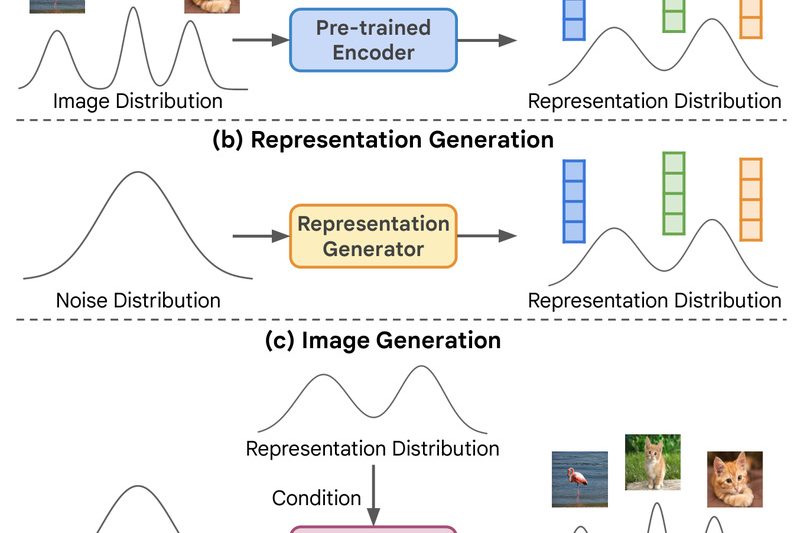
For years, unconditional image generation—creating realistic images without relying on human-provided class labels—has lagged significantly behind its class-conditional counterpart in…
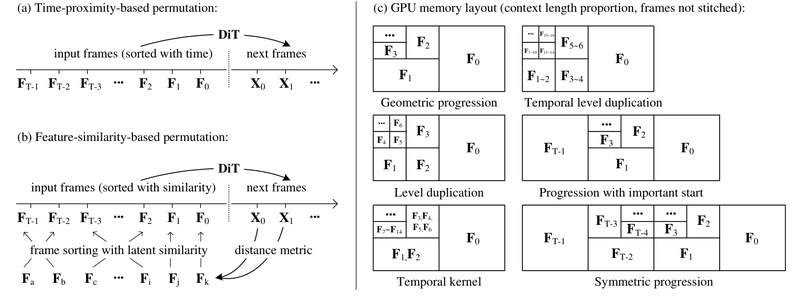
Creating long, coherent, and visually rich videos with AI has long been bottlenecked by computational complexity, memory constraints, and error…

Image super-resolution (SR) remains a critical capability across computer vision applications—from upscaling smartphone photos to enhancing AI-generated content (AIGC). However,…

OOTDiffusion represents a significant leap forward in image-based virtual try-on (VTON) technology. Built on the foundation of pretrained latent diffusion…
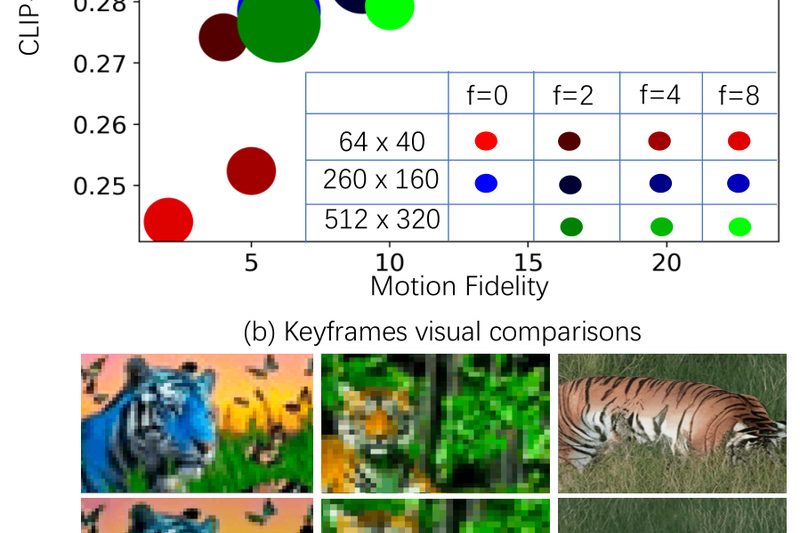
Text-to-video generation has rapidly evolved, yet technical teams still face a persistent trade-off: high-quality outputs often come at prohibitive computational…
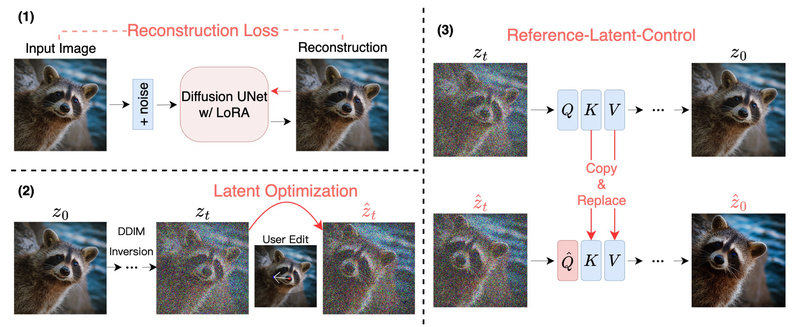
DragDiffusion is an open-source framework that brings pixel-precise, point-based image manipulation to both real-world photographs and AI-generated images—without requiring users…

Video generation using diffusion transformers (DiTs) is rapidly advancing—but at a steep computational cost. Full 3D attention in these models…

Creating high-quality 3D assets has traditionally required expert modeling skills, extensive manual labor, or expensive capture setups—barriers that limit accessibility…