Training large language models (LLMs) has traditionally been the domain of well-resourced AI labs with access to massive GPU clusters…

Training large language models (LLMs) has traditionally been the domain of well-resourced AI labs with access to massive GPU clusters…
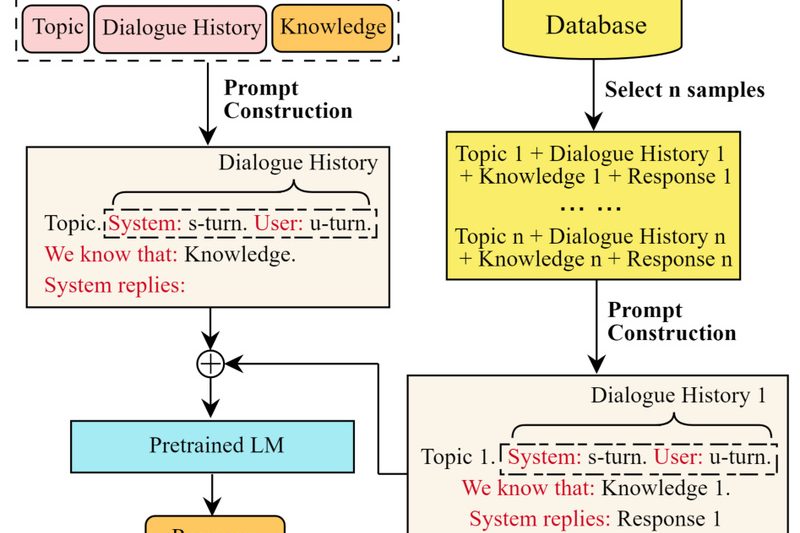
If you’re building or scaling large language models (LLMs) and have access to NVIDIA GPU clusters, Megatron-LM—developed by NVIDIA—is one…
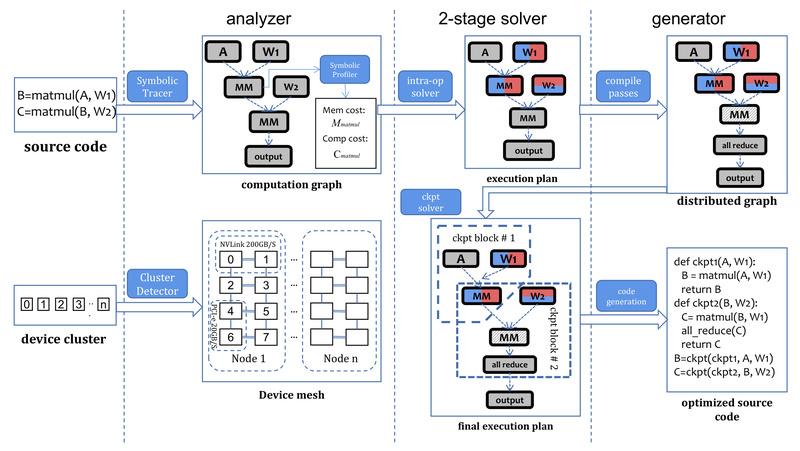
Training large-scale AI models—whether language models like LLaMA or video generators like Open-Sora—has become increasingly common, yet remains bottlenecked by…