Large language models (LLMs) are remarkably capable—but they often stumble when applied to specialized domains like finance, legal, healthcare, or…
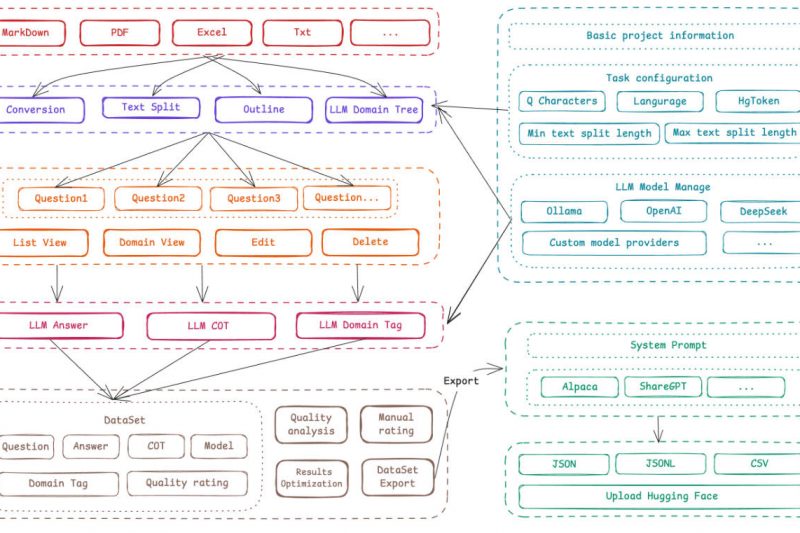
Large language models (LLMs) are remarkably capable—but they often stumble when applied to specialized domains like finance, legal, healthcare, or…