Large language models (LLMs) are becoming increasingly central to real-world applications—but their computational demands remain a major barrier for edge…
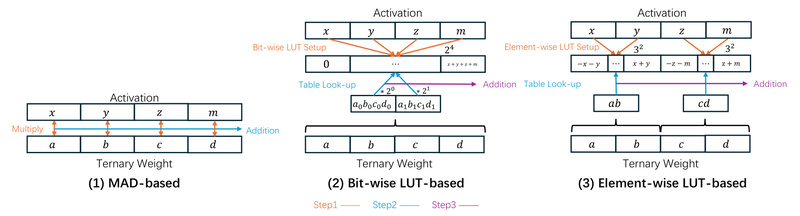
Large language models (LLMs) are becoming increasingly central to real-world applications—but their computational demands remain a major barrier for edge…