If you’re building or scaling a system that relies on large language models (LLMs)—whether for chatbots, embeddings, multimodal reasoning, or…
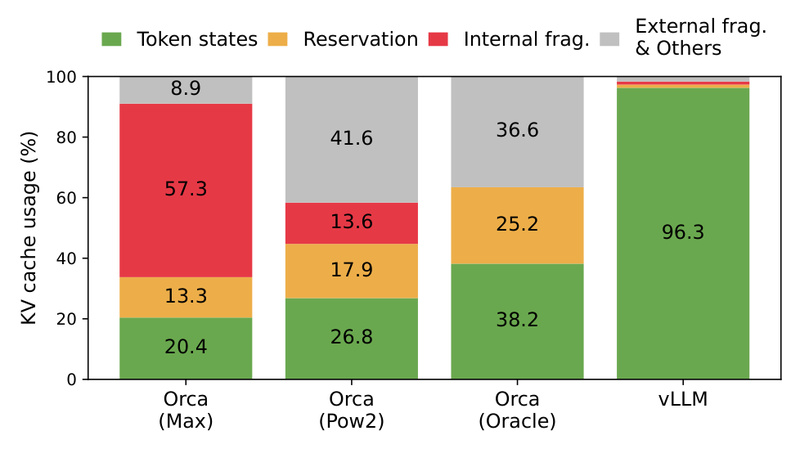
If you’re building or scaling a system that relies on large language models (LLMs)—whether for chatbots, embeddings, multimodal reasoning, or…
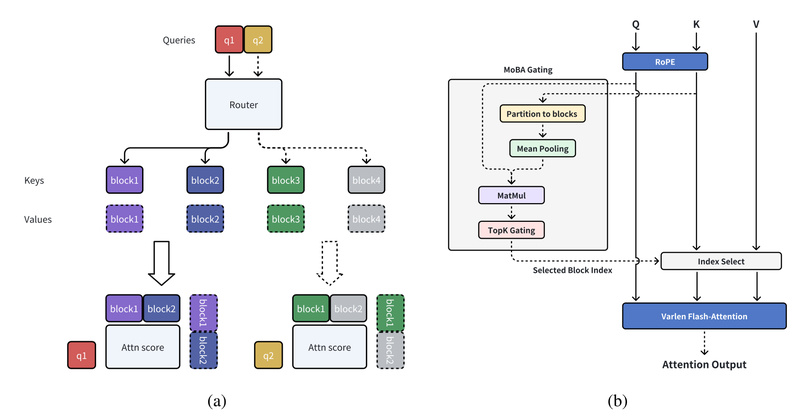
Handling long input sequences—ranging from tens of thousands to over a million tokens—is no longer a theoretical benchmark but a…