Building powerful language models used to be the exclusive domain of well-funded tech giants. But JetMoE is changing that narrative.…
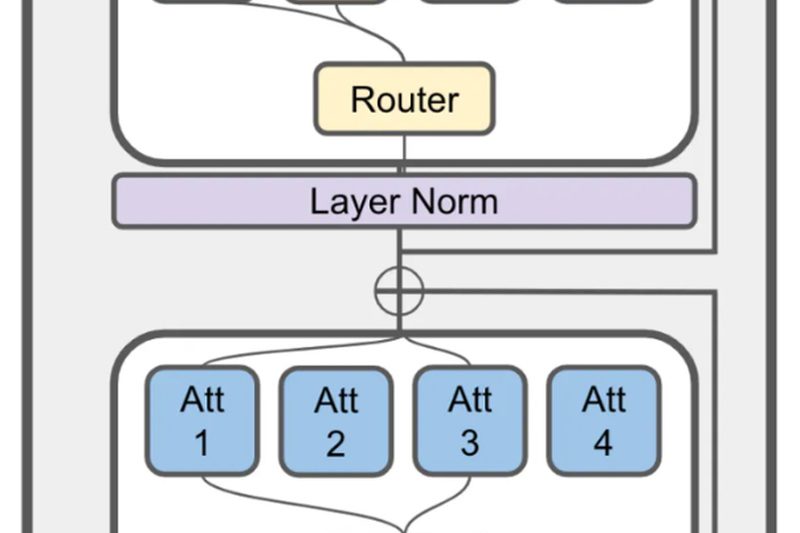
Building powerful language models used to be the exclusive domain of well-funded tech giants. But JetMoE is changing that narrative.…
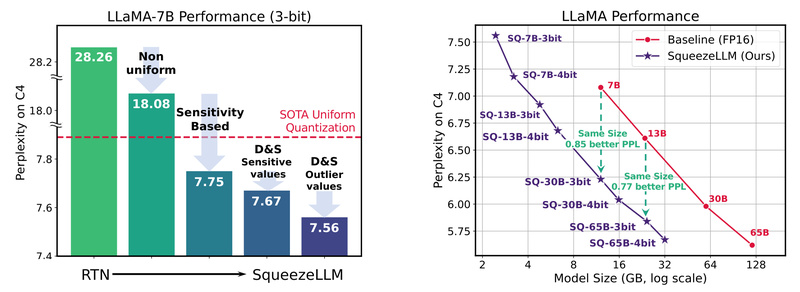
Deploying large language models (LLMs) like LLaMA, Mistral, or Vicuna often demands multiple high-end GPUs, complex inference pipelines, and substantial…
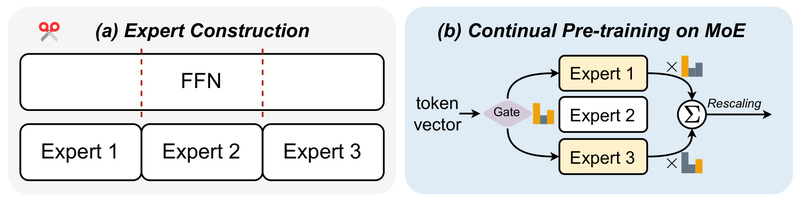
If you’re a developer, researcher, or technical decision-maker working with large language models (LLMs), you’ve likely faced a tough trade-off:…

Video generation using diffusion transformers (DiTs) has reached remarkable visual fidelity—but at a steep computational cost. The quadratic complexity of…
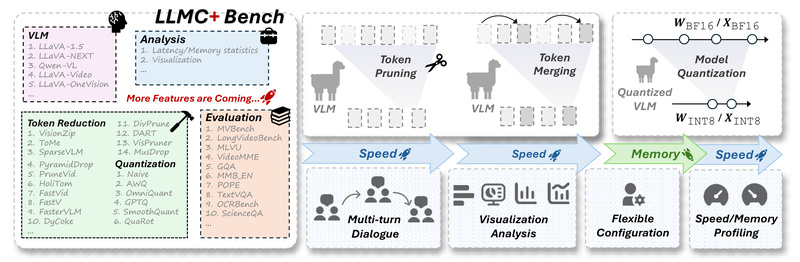
Deploying large vision-language models (VLMs) and large language models (LLMs) in real-world applications is often bottlenecked by their massive size,…
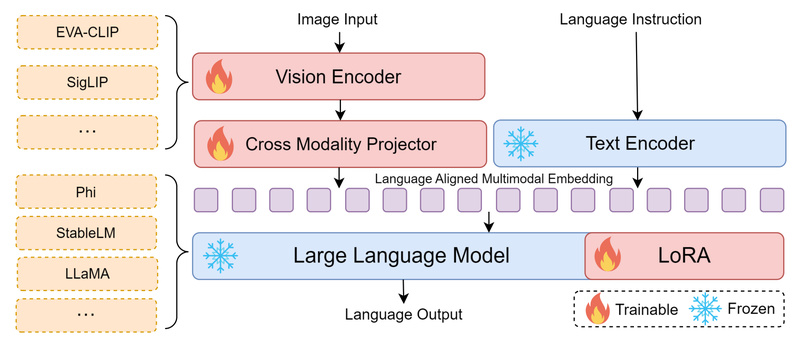
Multimodal Large Language Models (MLLMs) are transforming how machines understand and reason about visual content. Yet, their adoption remains out…

Deploying large AI models in production often involves a fragmented toolchain: one set of libraries for training, another for quantization,…