For teams deploying large language models (LLMs) in production—whether for chatbots, reasoning APIs, or batch processing—latency and inference cost are…
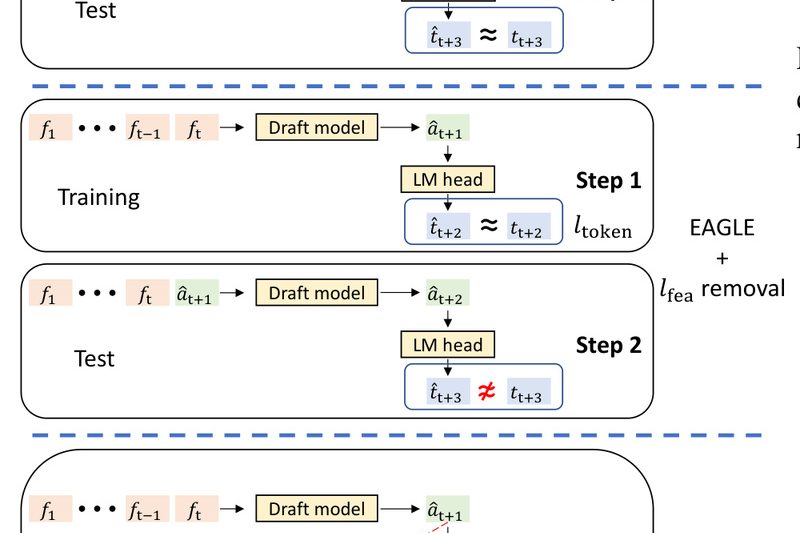
For teams deploying large language models (LLMs) in production—whether for chatbots, reasoning APIs, or batch processing—latency and inference cost are…