Deploying large language models (LLMs) to handle long documents, extensive chat histories, or detailed technical manuals remains a major bottleneck…
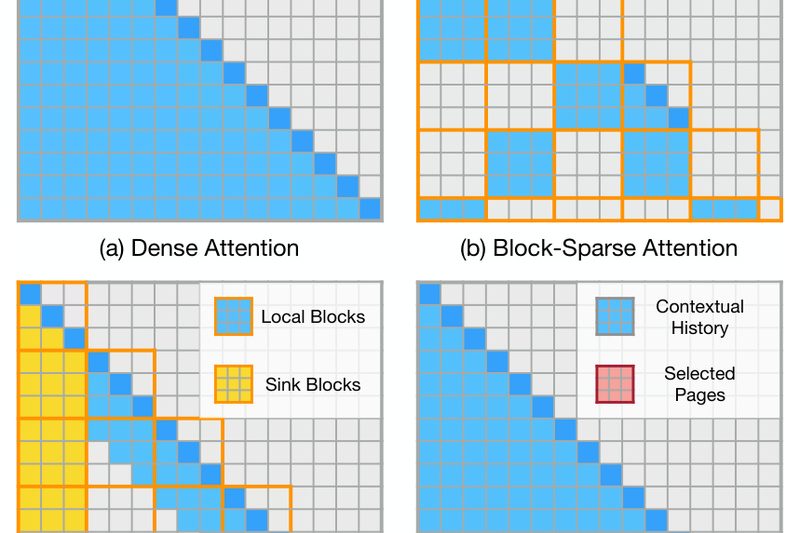
Deploying large language models (LLMs) to handle long documents, extensive chat histories, or detailed technical manuals remains a major bottleneck…
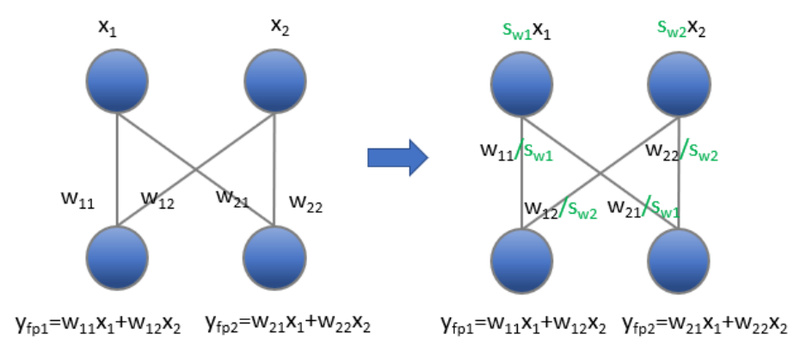
Deploying large language models (LLMs) in production often runs into a hard trade-off: reduce model size and latency through quantization,…