Creating lifelike digital avatars that speak naturally with accurate lip movements and rich emotional expression has long been a challenge…
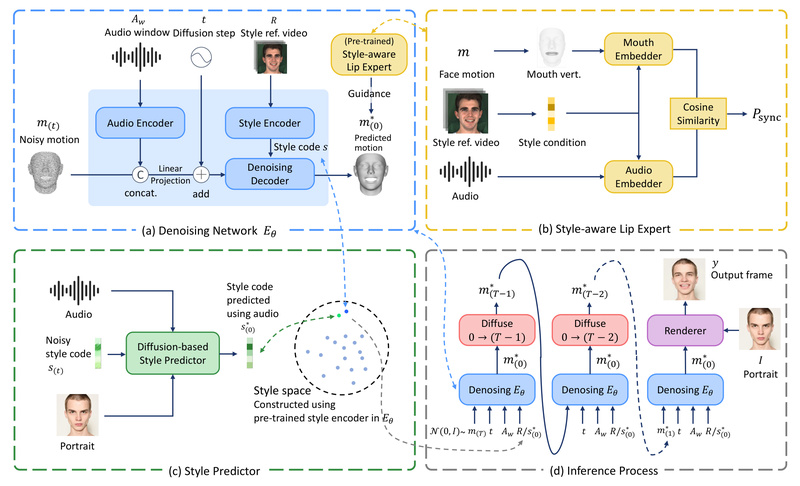
Creating lifelike digital avatars that speak naturally with accurate lip movements and rich emotional expression has long been a challenge…