When large language models (LLMs) generate code, how do you know it’s actually correct? Traditional code evaluation benchmarks like HumanEval…
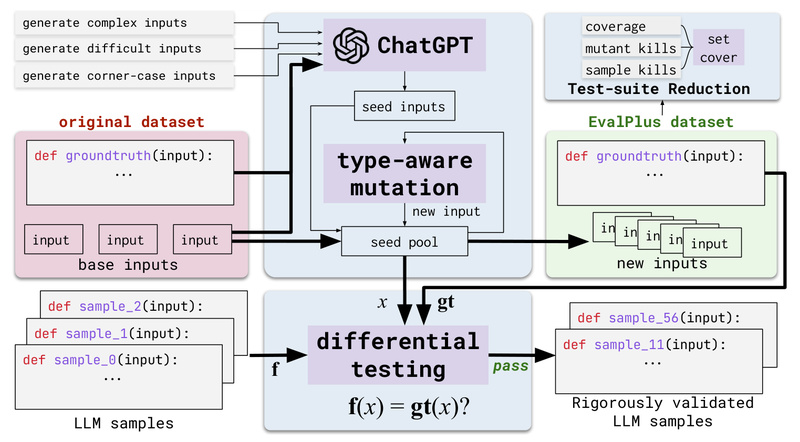
When large language models (LLMs) generate code, how do you know it’s actually correct? Traditional code evaluation benchmarks like HumanEval…