Vision Transformers (ViTs) have become a cornerstone of modern computer vision, offering strong performance across a wide range of tasks.…
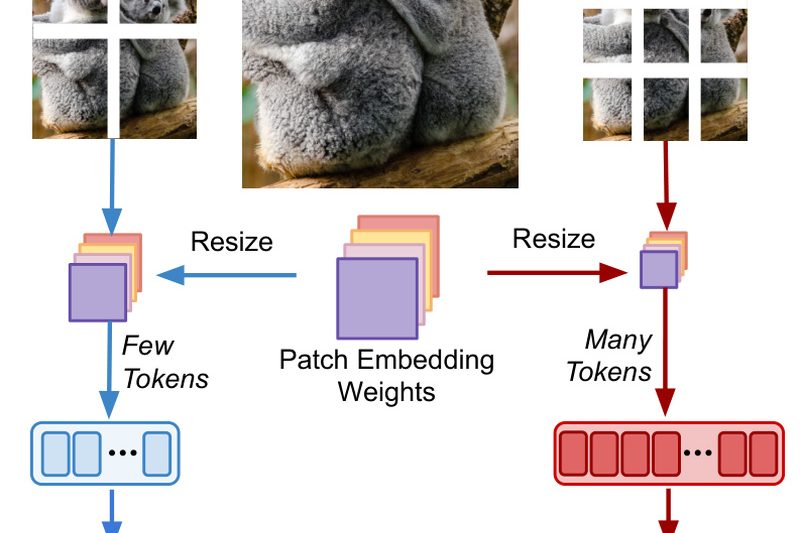
Vision Transformers (ViTs) have become a cornerstone of modern computer vision, offering strong performance across a wide range of tasks.…