SmolVLA is a compact yet capable Vision-Language-Action (VLA) model designed to bring state-of-the-art robot control within reach of researchers, educators,…
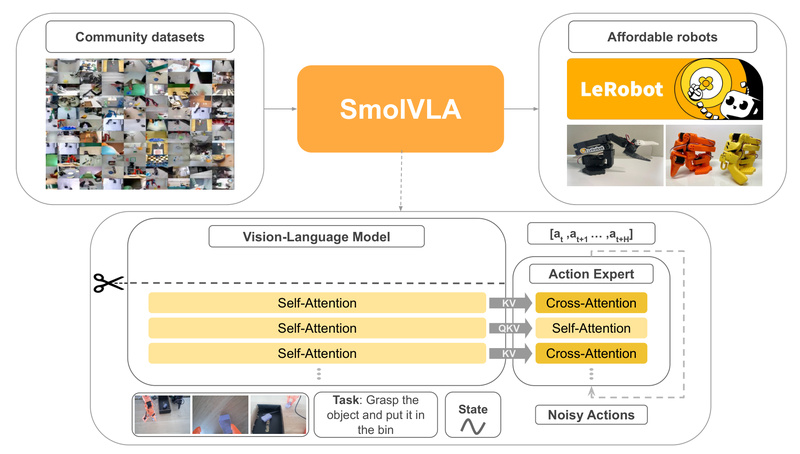
SmolVLA is a compact yet capable Vision-Language-Action (VLA) model designed to bring state-of-the-art robot control within reach of researchers, educators,…