In today’s AI-driven product landscape, the ability to understand both images and text isn’t just a research novelty—it’s a practical…
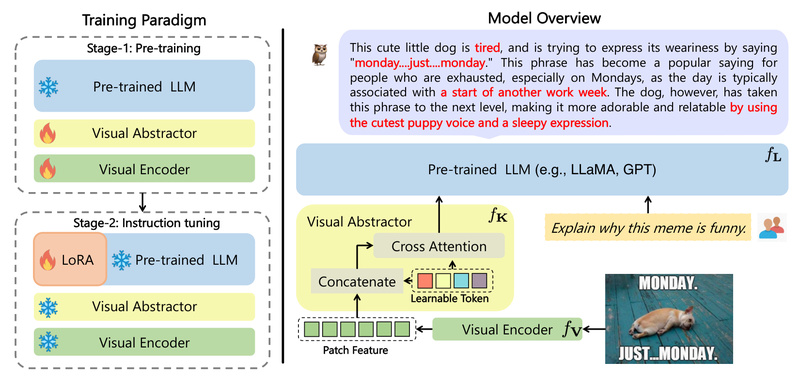
In today’s AI-driven product landscape, the ability to understand both images and text isn’t just a research novelty—it’s a practical…