Building powerful language models used to be the exclusive domain of well-funded tech giants. But JetMoE is changing that narrative.…
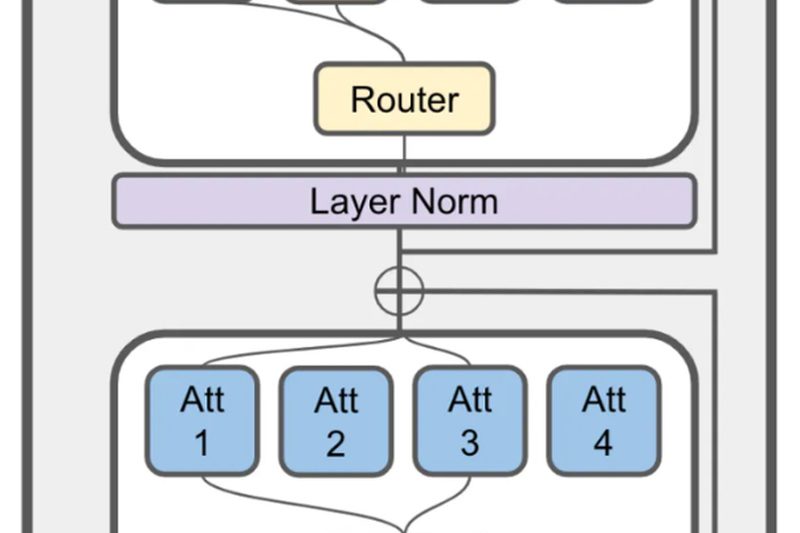
Building powerful language models used to be the exclusive domain of well-funded tech giants. But JetMoE is changing that narrative.…

Large AI models—from language generators to video diffusion systems—are bottlenecked by the attention mechanism, whose computational cost scales quadratically with…
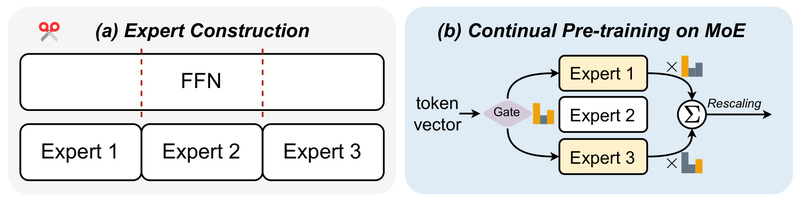
If you’re a developer, researcher, or technical decision-maker working with large language models (LLMs), you’ve likely faced a tough trade-off:…