Aligning large language models (LLMs) with human preferences is essential for building safe, helpful, and reliable AI systems. Reinforcement Learning…
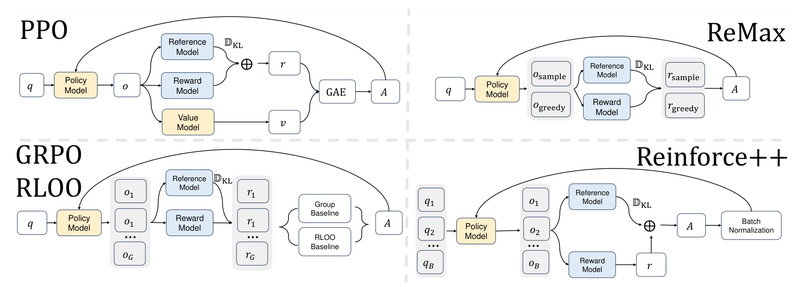
Aligning large language models (LLMs) with human preferences is essential for building safe, helpful, and reliable AI systems. Reinforcement Learning…
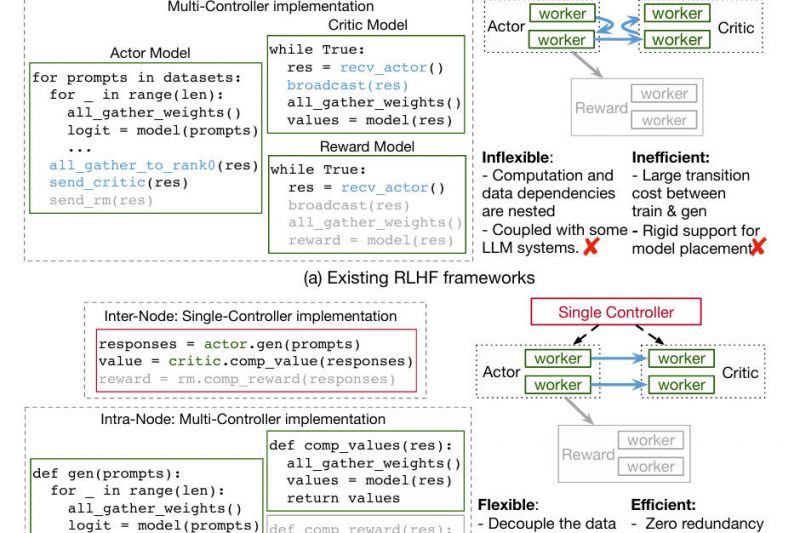
Verl (short for Volcano Engine Reinforcement Learning) is an open-source, production-ready framework designed specifically for Reinforcement Learning from Human Feedback…