Deploying large language models (LLMs) like LLaMA, Mistral, or Vicuna often demands multiple high-end GPUs, complex inference pipelines, and substantial…
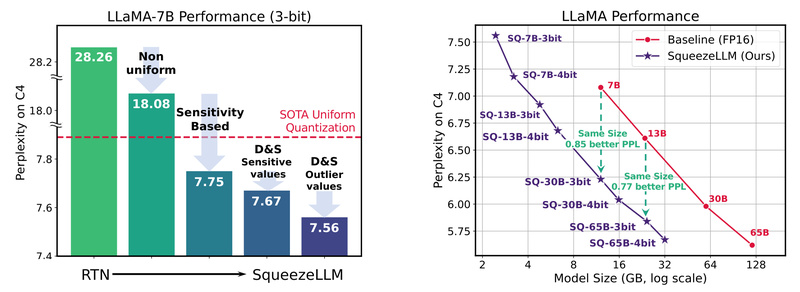
Deploying large language models (LLMs) like LLaMA, Mistral, or Vicuna often demands multiple high-end GPUs, complex inference pipelines, and substantial…
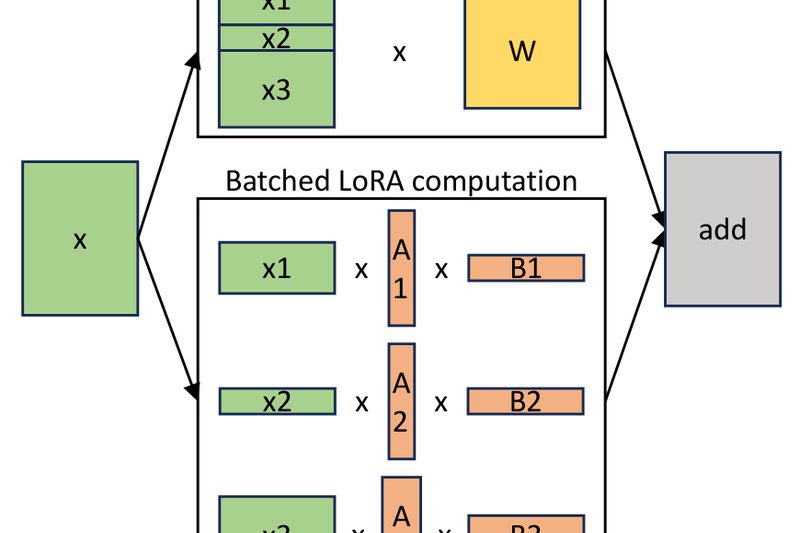
Deploying dozens—or even thousands—of fine-tuned large language models (LLMs) has traditionally been a costly and complex endeavor. Each adapter typically…
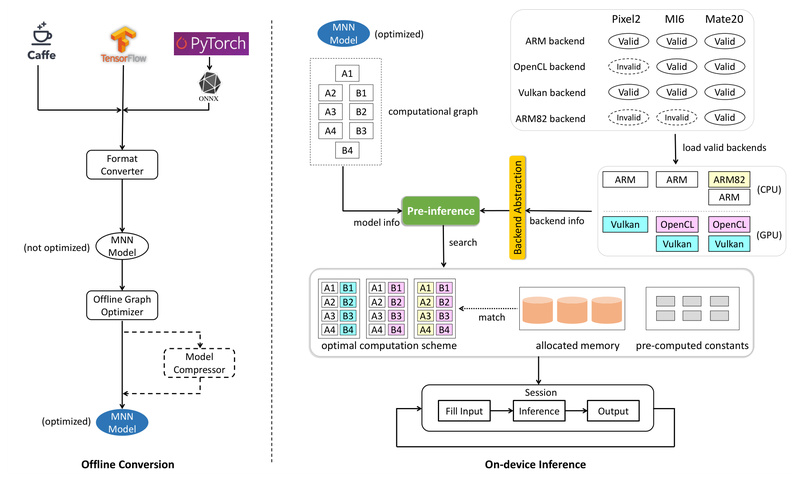
Mobile Neural Network (MNN) is an open-source, lightweight deep learning inference engine developed by Alibaba Group to bring powerful AI…