Deploying large language models (LLMs) in production is expensive—not just in dollars, but in compute and memory. While models like…
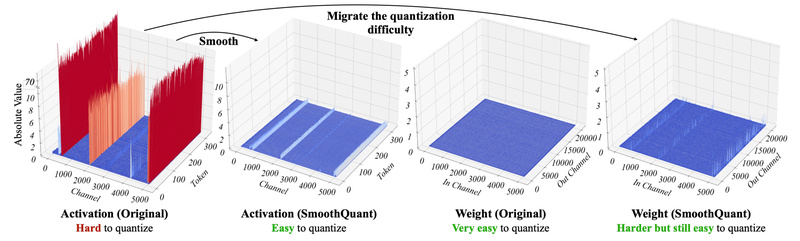
Deploying large language models (LLMs) in production is expensive—not just in dollars, but in compute and memory. While models like…

Attention mechanisms lie at the heart of modern large language models (LLMs) and multimodal architectures—but their quadratic computational complexity remains…