Evaluating large language models (LLMs) on new tasks traditionally requires fine-tuning—a process that’s time-consuming, resource-intensive, and often impractical when labeled…
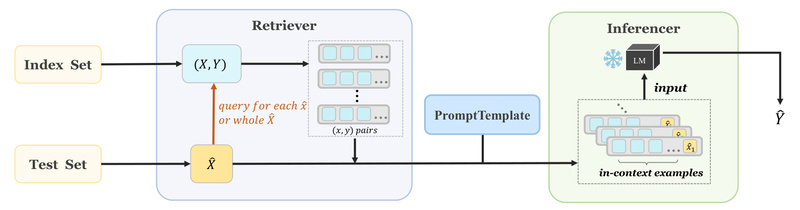
Evaluating large language models (LLMs) on new tasks traditionally requires fine-tuning—a process that’s time-consuming, resource-intensive, and often impractical when labeled…
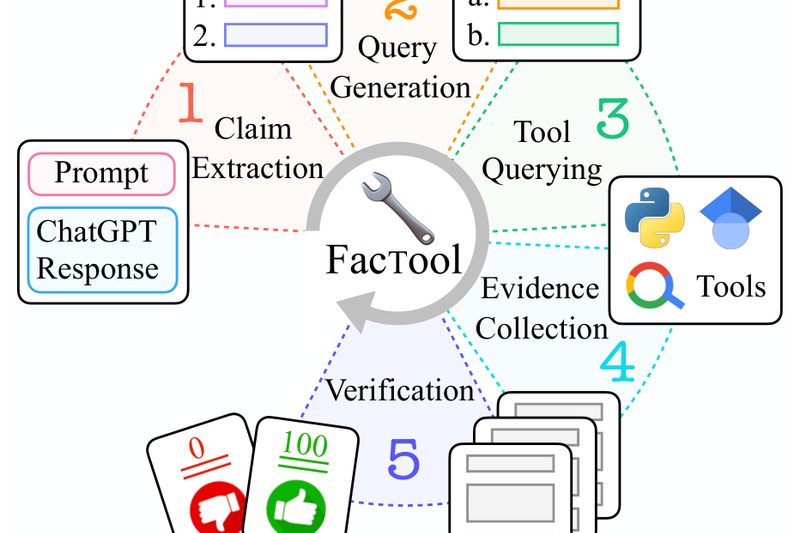
Large language models (LLMs) like ChatGPT and GPT-4 have transformed how we generate text, write code, solve math problems, and…