Deploying large language models (LLMs) at scale introduces a familiar bottleneck: the growing size of Key-Value (KV) caches rapidly outpaces…
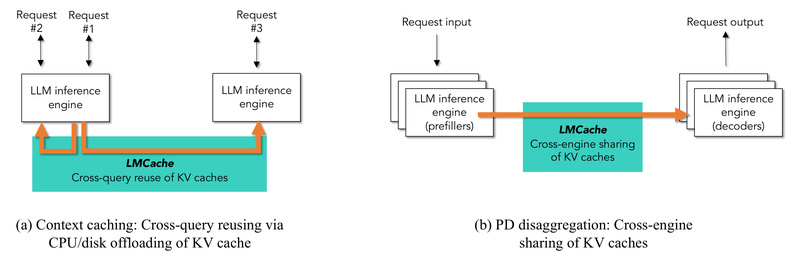
Deploying large language models (LLMs) at scale introduces a familiar bottleneck: the growing size of Key-Value (KV) caches rapidly outpaces…