Deploying large language models (LLMs) to handle long documents, extensive chat histories, or detailed technical manuals remains a major bottleneck…
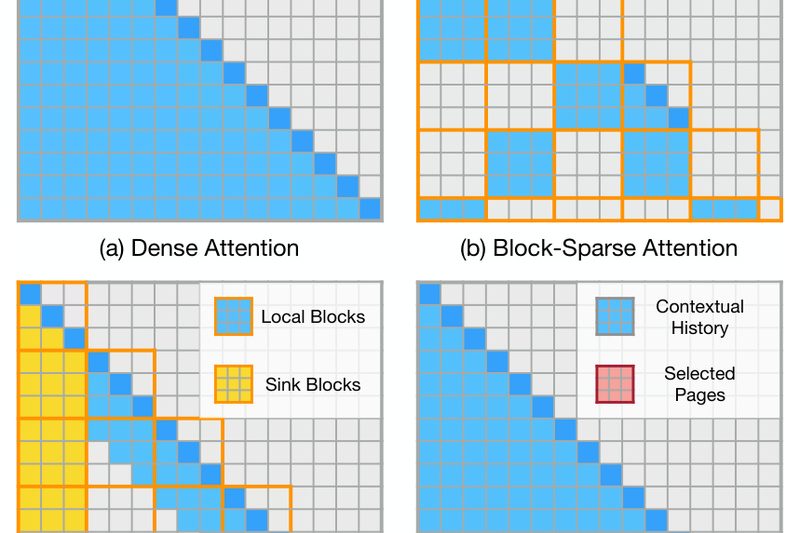
Deploying large language models (LLMs) to handle long documents, extensive chat histories, or detailed technical manuals remains a major bottleneck…
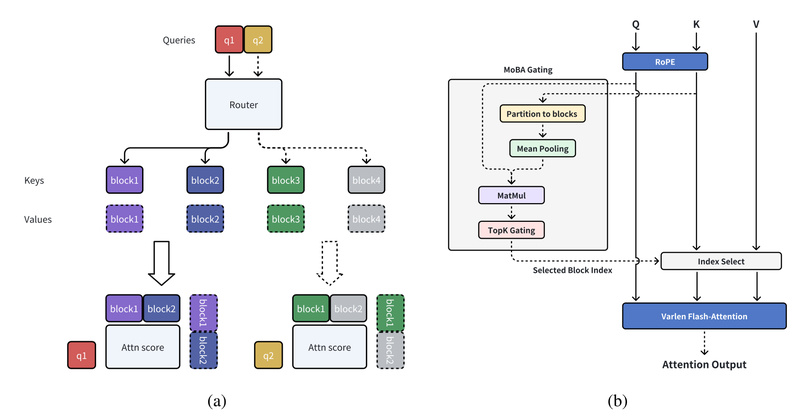
Handling long input sequences—ranging from tens of thousands to over a million tokens—is no longer a theoretical benchmark but a…