If you’re building AI systems that require reliable, step-by-step mathematical reasoning—but don’t have access to proprietary datasets, massive compute budgets,…
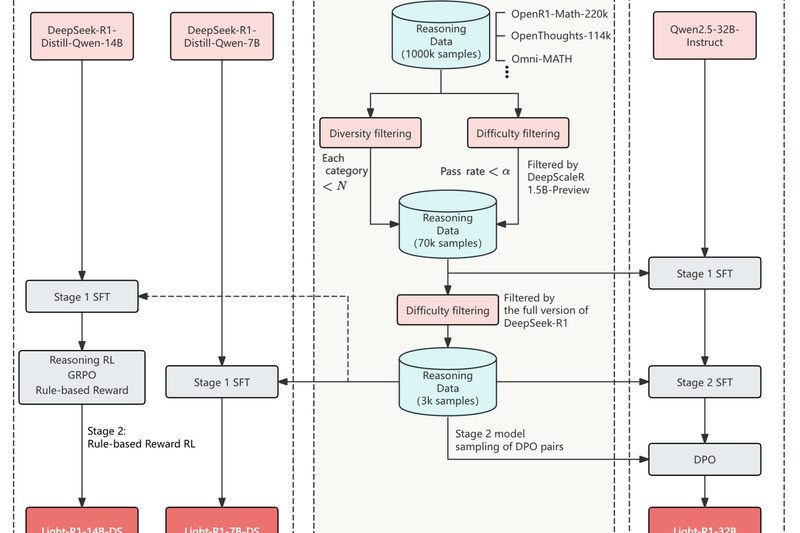
If you’re building AI systems that require reliable, step-by-step mathematical reasoning—but don’t have access to proprietary datasets, massive compute budgets,…
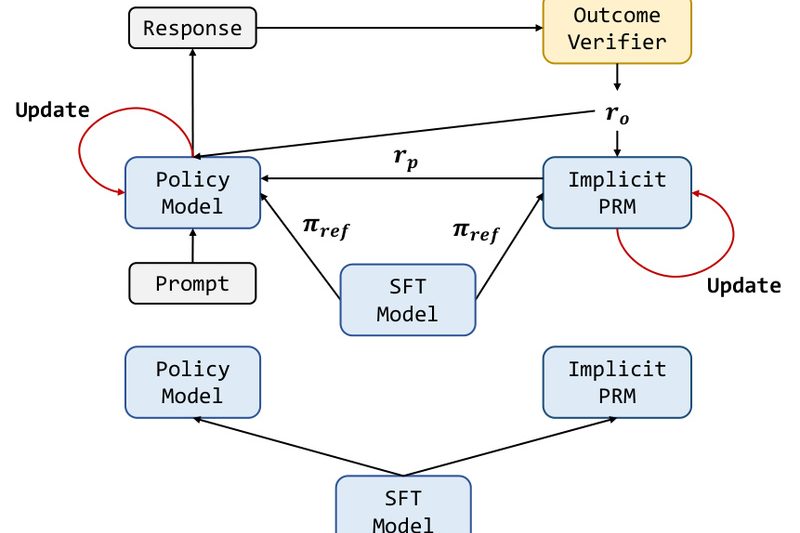
If you’re working to improve large language models (LLMs) on hard reasoning tasks—like math problem solving or competitive programming—you’ve likely…
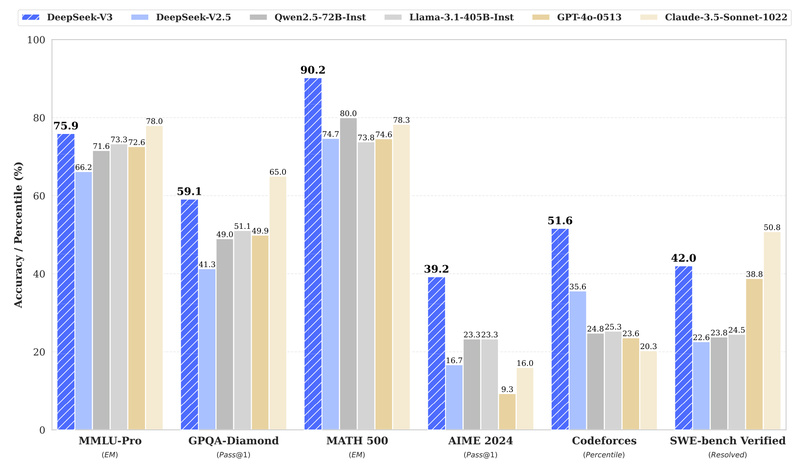
For technical decision-makers evaluating large language models (LLMs) for real-world applications, balancing raw capability, inference cost, training efficiency, and deployment…
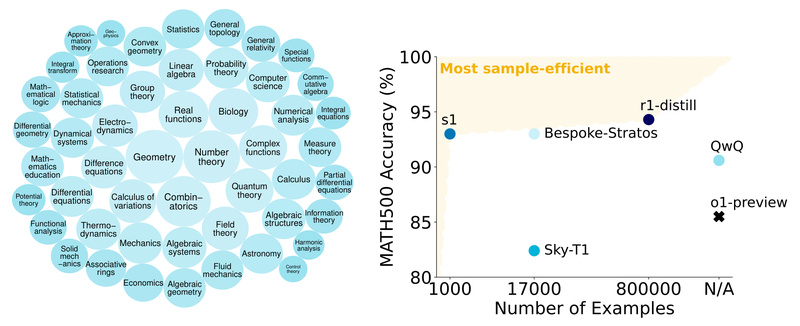
In the rapidly evolving landscape of large language models (LLMs), achieving strong reasoning capabilities often comes at the cost of…
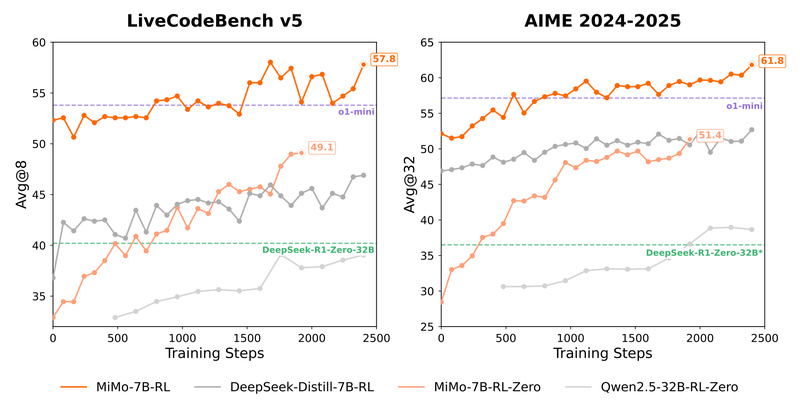
MiMo is a 7-billion-parameter language model purpose-built for reasoning-intensive tasks—spanning mathematics, code generation, and STEM problem solving—without the computational overhead…
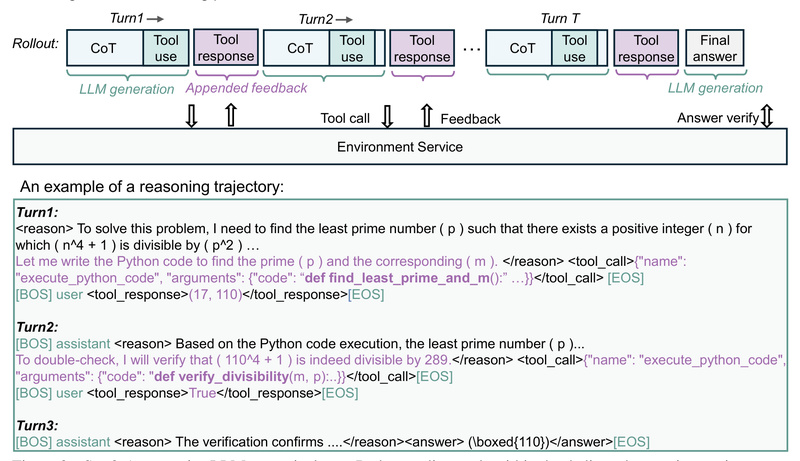
In the rapidly evolving landscape of large language models (LLMs), bigger isn’t always better—smarter is. Enter rStar2-Agent, a 14-billion-parameter reasoning…