Vision Transformers (ViTs) have revolutionized computer vision, but their computational demands remain a major barrier for real-world deployment—especially on edge…
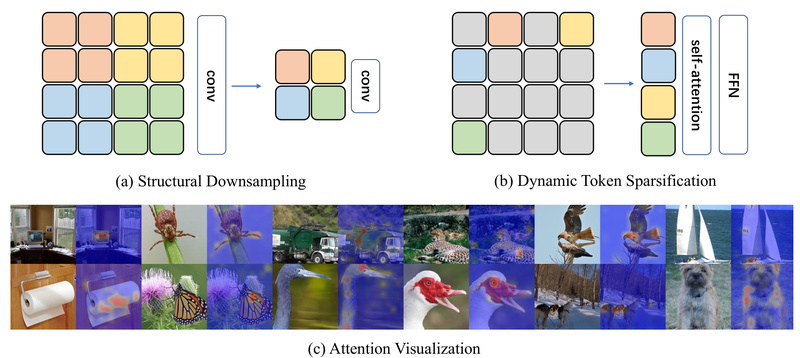
Vision Transformers (ViTs) have revolutionized computer vision, but their computational demands remain a major barrier for real-world deployment—especially on edge…