Deploying large vision-language models (VLMs) and large language models (LLMs) in real-world applications is often bottlenecked by their massive size,…
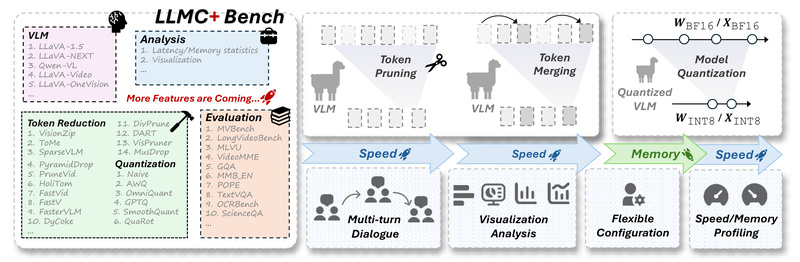
Deploying large vision-language models (VLMs) and large language models (LLMs) in real-world applications is often bottlenecked by their massive size,…