Deploying large language models (LLMs) like LLaMA, Mistral, or Vicuna often demands multiple high-end GPUs, complex inference pipelines, and substantial…
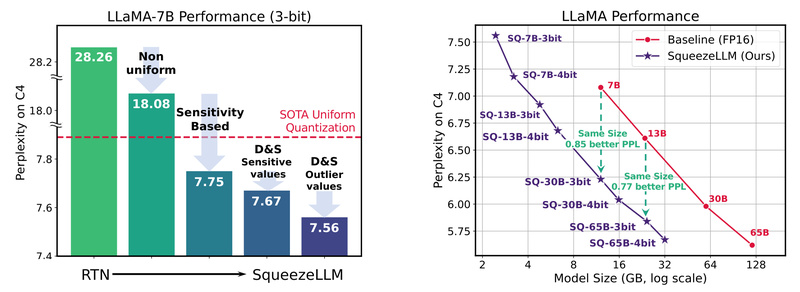
Deploying large language models (LLMs) like LLaMA, Mistral, or Vicuna often demands multiple high-end GPUs, complex inference pipelines, and substantial…

Deploying large AI models in production often involves a fragmented toolchain: one set of libraries for training, another for quantization,…