If you’re building or scaling a system that relies on large language models (LLMs)—whether for chatbots, embeddings, multimodal reasoning, or…
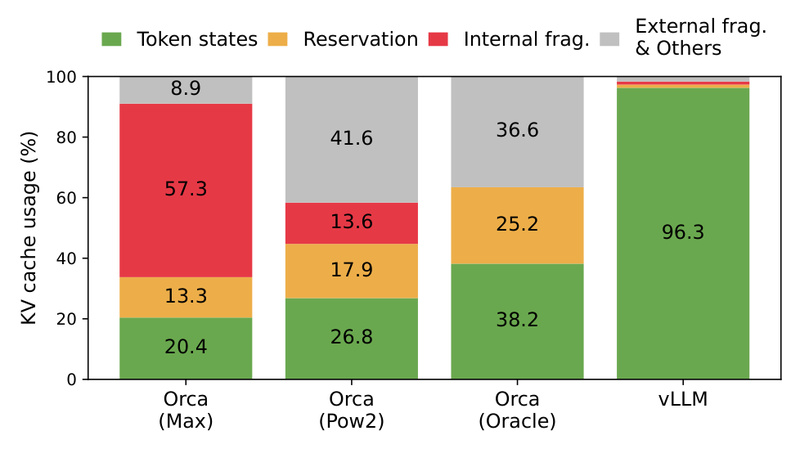
If you’re building or scaling a system that relies on large language models (LLMs)—whether for chatbots, embeddings, multimodal reasoning, or…
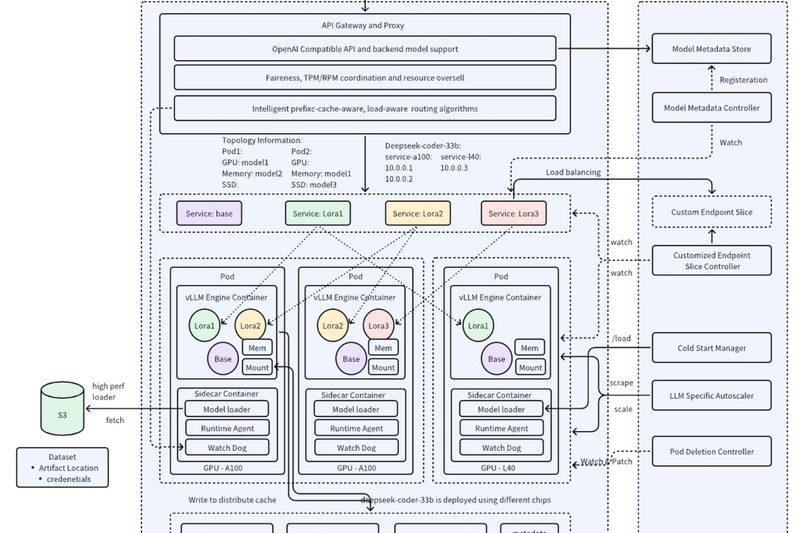
Deploying large language models (LLMs) at scale in production environments remains a significant challenge for engineering teams. High inference costs,…