Deploying dozens—or even thousands—of fine-tuned large language models (LLMs) has traditionally been a costly and complex endeavor. Each adapter typically…
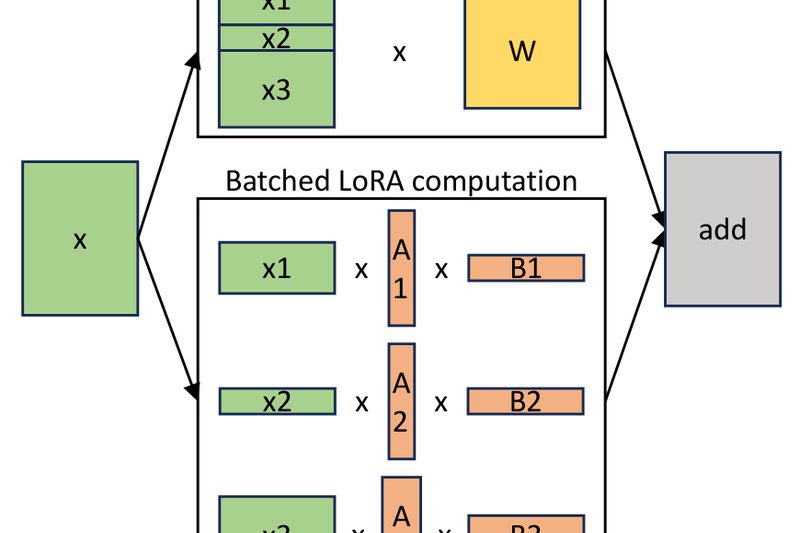
Deploying dozens—or even thousands—of fine-tuned large language models (LLMs) has traditionally been a costly and complex endeavor. Each adapter typically…