Verl (short for Volcano Engine Reinforcement Learning) is an open-source, production-ready framework designed specifically for Reinforcement Learning from Human Feedback…
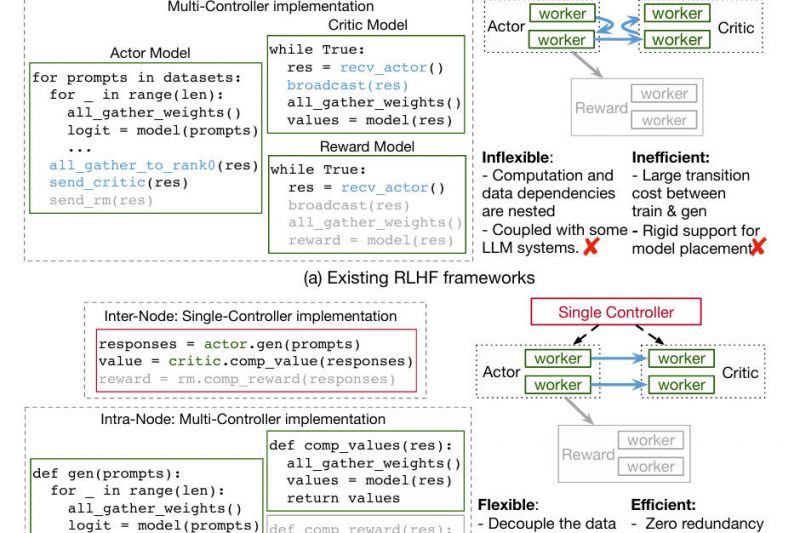
Verl (short for Volcano Engine Reinforcement Learning) is an open-source, production-ready framework designed specifically for Reinforcement Learning from Human Feedback…