Deploying multiple fine-tuned large language models (LLMs) used to mean multiplying your GPU costs—until Punica arrived. If you’re managing dozens…
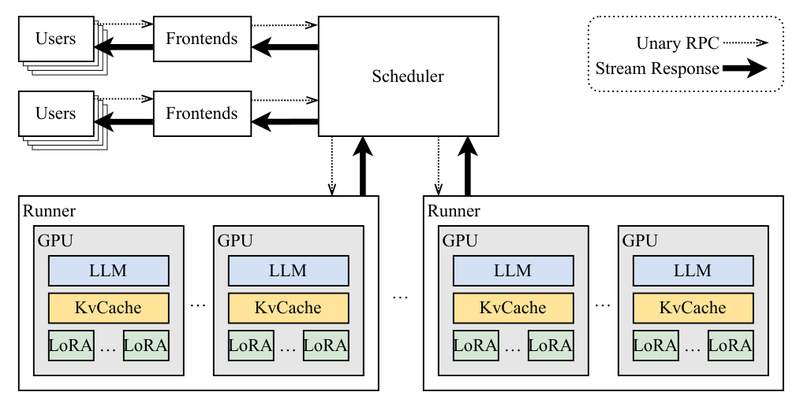
Deploying multiple fine-tuned large language models (LLMs) used to mean multiplying your GPU costs—until Punica arrived. If you’re managing dozens…