If your team is building AI applications that need to see, reason, and act—like desktop assistants that interpret screenshots, UI…
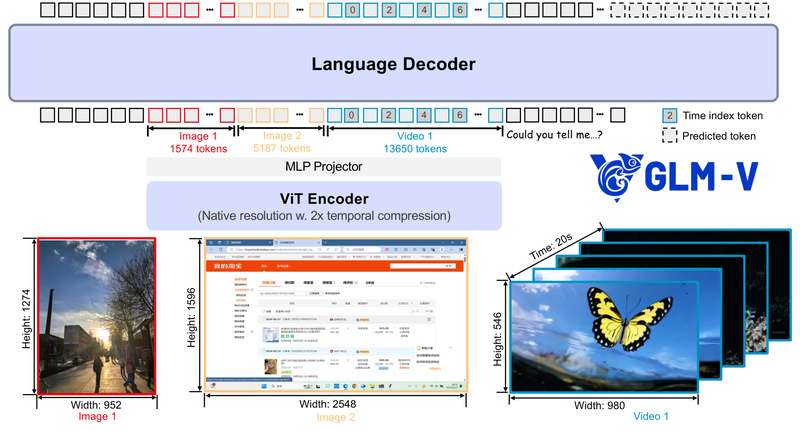
If your team is building AI applications that need to see, reason, and act—like desktop assistants that interpret screenshots, UI…