Multimodal Large Language Models (MLLMs) have captured the imagination of researchers and developers alike—promising capabilities like generating poetry from images,…
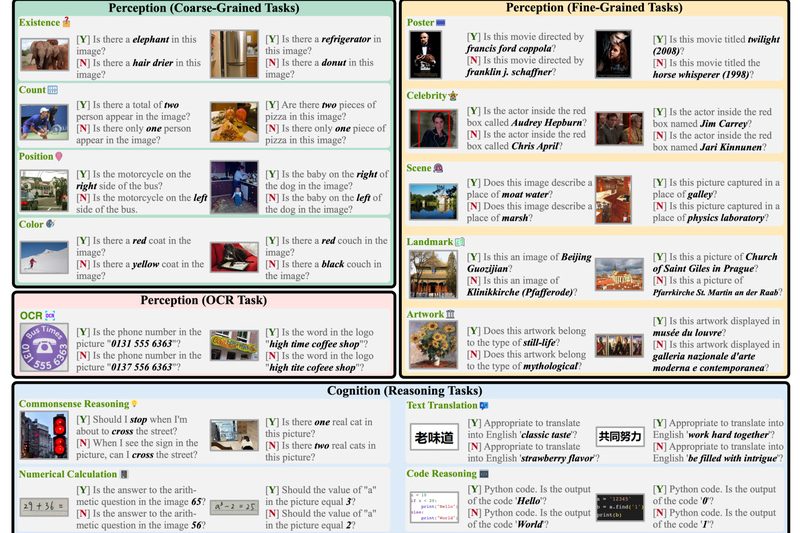
Multimodal Large Language Models (MLLMs) have captured the imagination of researchers and developers alike—promising capabilities like generating poetry from images,…