Multimodal Large Language Models (MLLMs) are increasingly vital for tasks that bridge vision and language—yet many struggle to truly fuse…
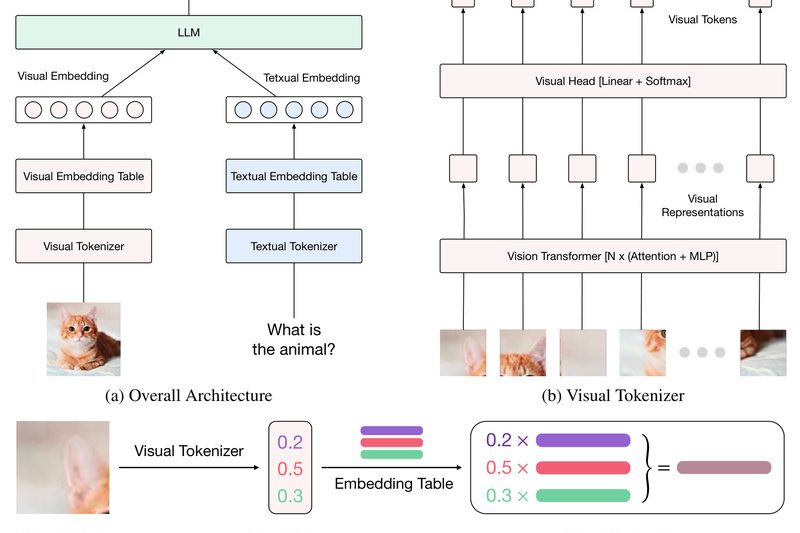
Multimodal Large Language Models (MLLMs) are increasingly vital for tasks that bridge vision and language—yet many struggle to truly fuse…