Step-Video-T2V is a state-of-the-art open-source text-to-video foundation model developed by StepFun AI. With 30 billion parameters and the ability to…
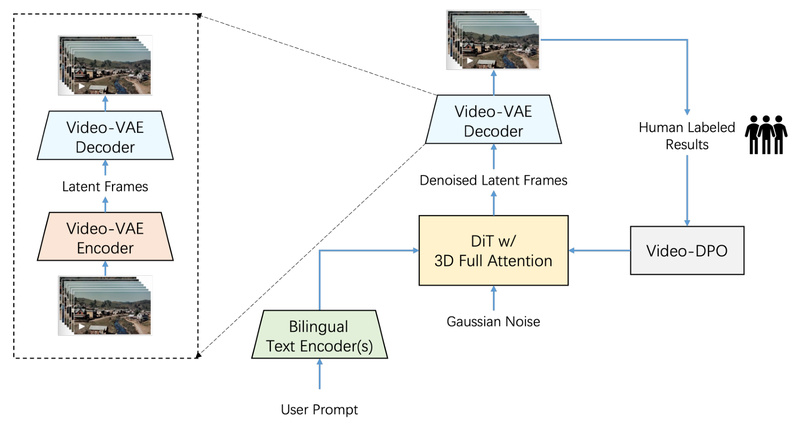
Step-Video-T2V is a state-of-the-art open-source text-to-video foundation model developed by StepFun AI. With 30 billion parameters and the ability to…