LeVo is a breakthrough in open-source AI music generation. Unlike many existing tools that produce fragmented, low-quality, or inconsistent audio,…
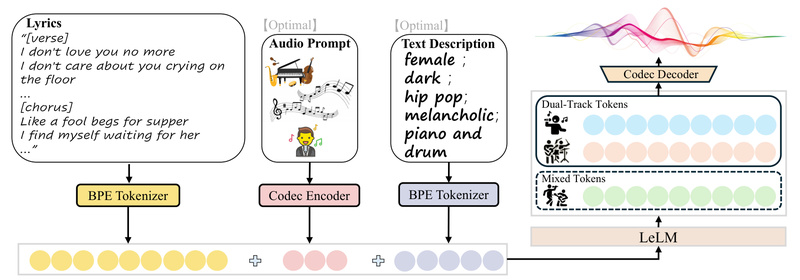
LeVo is a breakthrough in open-source AI music generation. Unlike many existing tools that produce fragmented, low-quality, or inconsistent audio,…
Building speech language models (SpeechLMs)—systems that jointly understand and generate both speech and text—is rapidly becoming essential for next-generation voice…