In today’s AI landscape, multimodal systems that understand both images and videos are increasingly essential—but most solutions force you to…
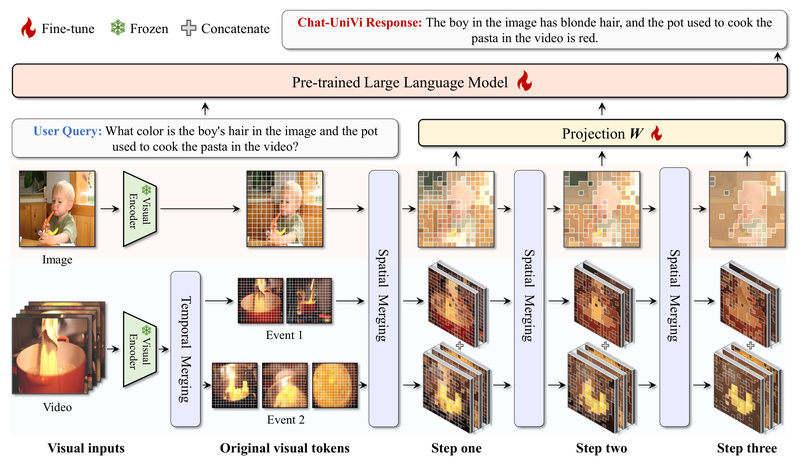
In today’s AI landscape, multimodal systems that understand both images and videos are increasingly essential—but most solutions force you to…
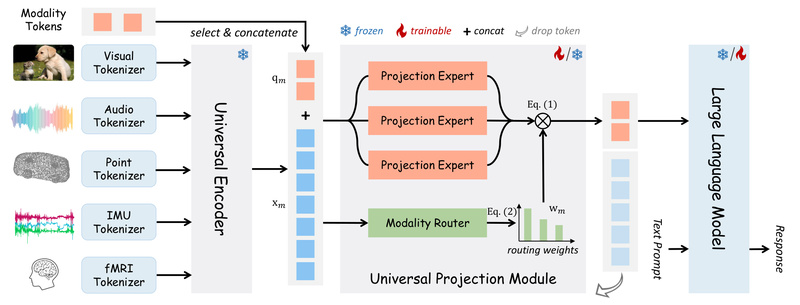
Multimodal AI is no longer just about images and text—it’s about seamlessly blending diverse data streams like audio, video, 3D…
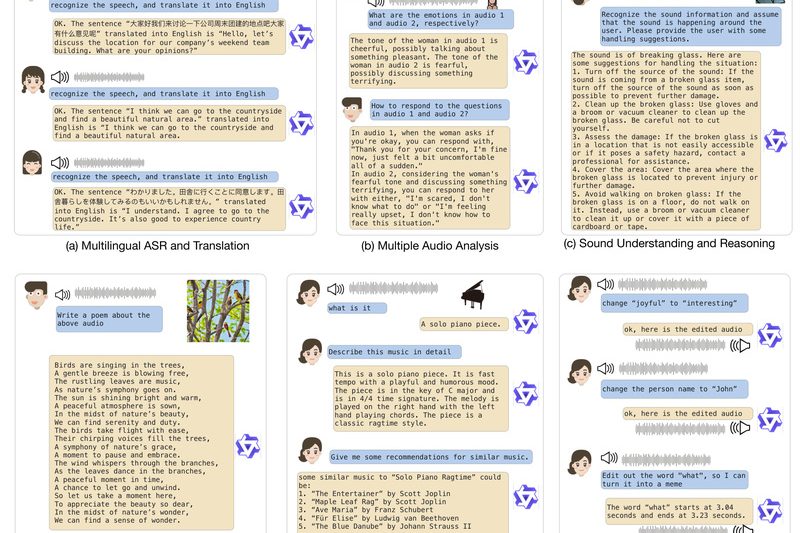
Audio is one of the richest yet most fragmented modalities in artificial intelligence. Traditional systems often require separate models for…

In today’s open-source AI landscape, building truly multimodal applications often means stitching together separate models for vision, speech recognition (ASR),…

If you’re evaluating vision-language models for a project that involves both images and videos, you’ve probably faced a frustrating trade-off:…

Overview For technical decision makers evaluating multimodal AI, choosing between closed-source APIs and open alternatives often means trading off control,…
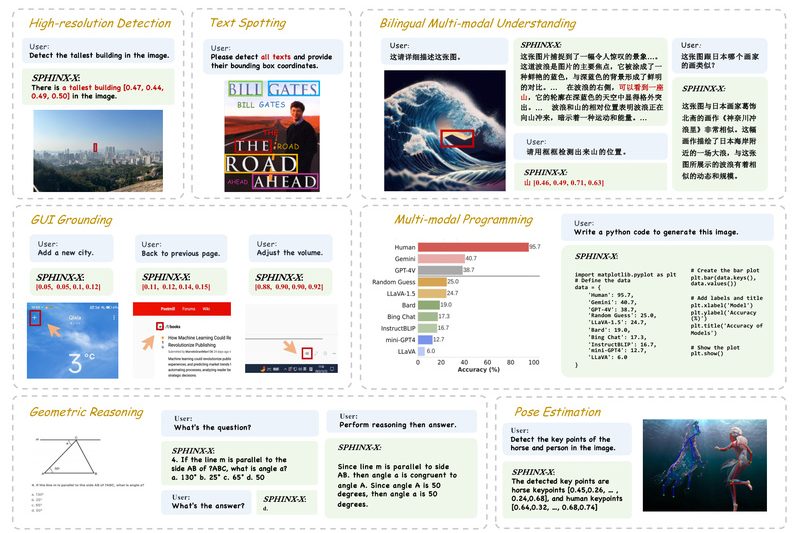
SPHINX-X is a next-generation family of Multimodal Large Language Models (MLLMs) designed to streamline the development, training, and deployment of…

In today’s AI landscape, developers and researchers often juggle separate models for vision, language, and video—each with its own architecture,…

Parsing complex document images—those containing intertwined text paragraphs, tables, mathematical formulas, figures, and code—is a persistent challenge in applied AI.…

Converting real-world documents—especially PDFs containing mixed content like equations, tables, multi-column layouts, and scanned text—into clean, structured, machine-readable formats remains…