MoE-LLaVA (Mixture of Experts for Large Vision-Language Models) redefines efficiency in multimodal AI by delivering performance that rivals much larger…
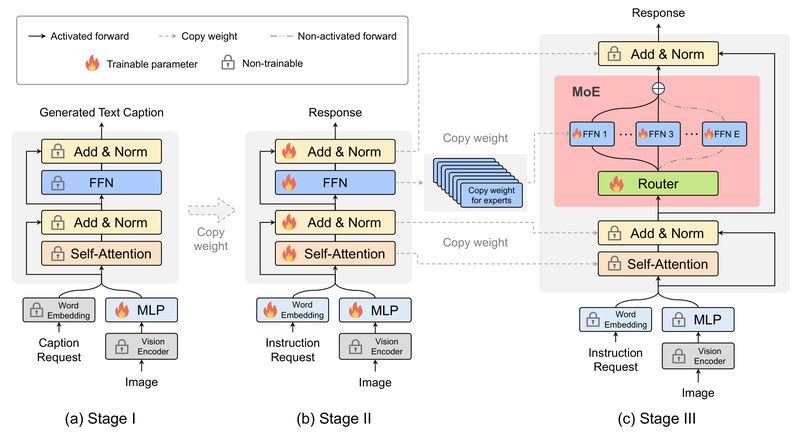
MoE-LLaVA (Mixture of Experts for Large Vision-Language Models) redefines efficiency in multimodal AI by delivering performance that rivals much larger…