TinyLlama is a compact yet powerful open-source language model with just 1.1 billion parameters—but trained on an impressive 3 trillion…
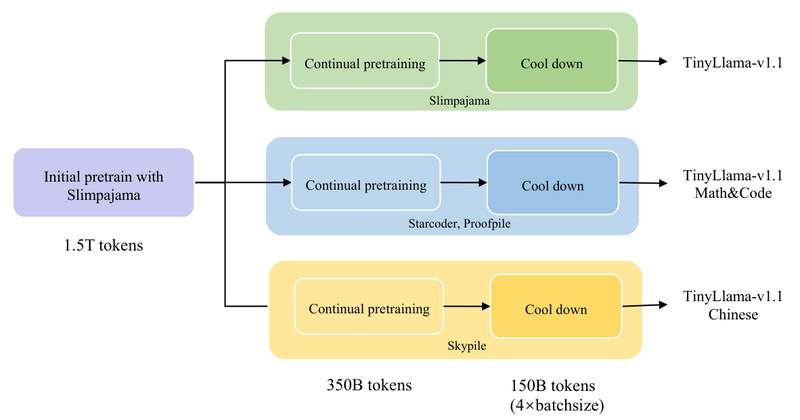
TinyLlama is a compact yet powerful open-source language model with just 1.1 billion parameters—but trained on an impressive 3 trillion…
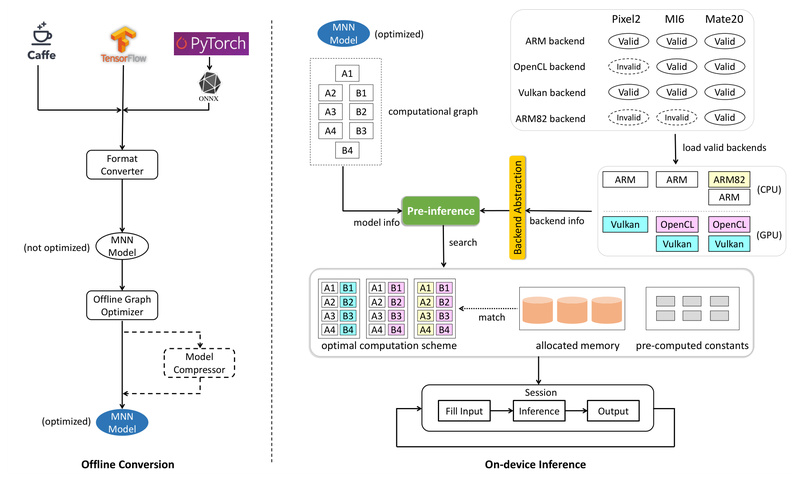
Mobile Neural Network (MNN) is an open-source, lightweight deep learning inference engine developed by Alibaba Group to bring powerful AI…
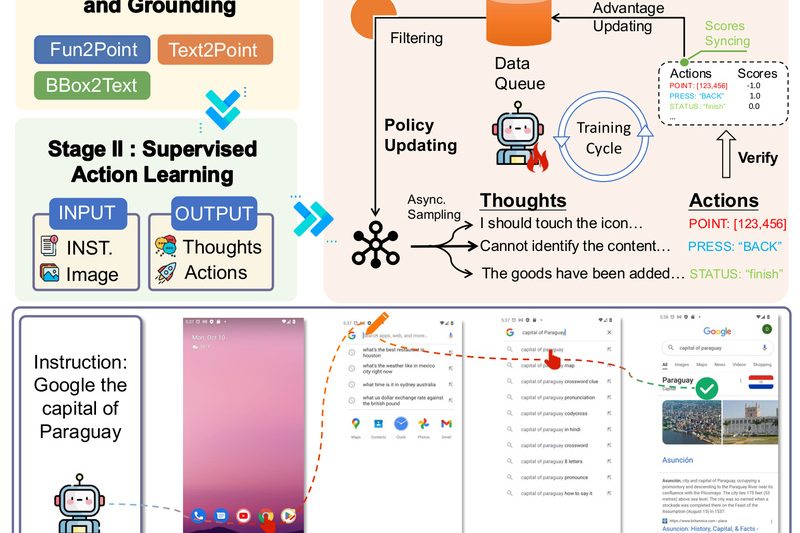
AgentCPM-GUI is an open-source, on-device large language model (LLM) agent designed to understand smartphone screenshots and autonomously perform user-specified tasks…
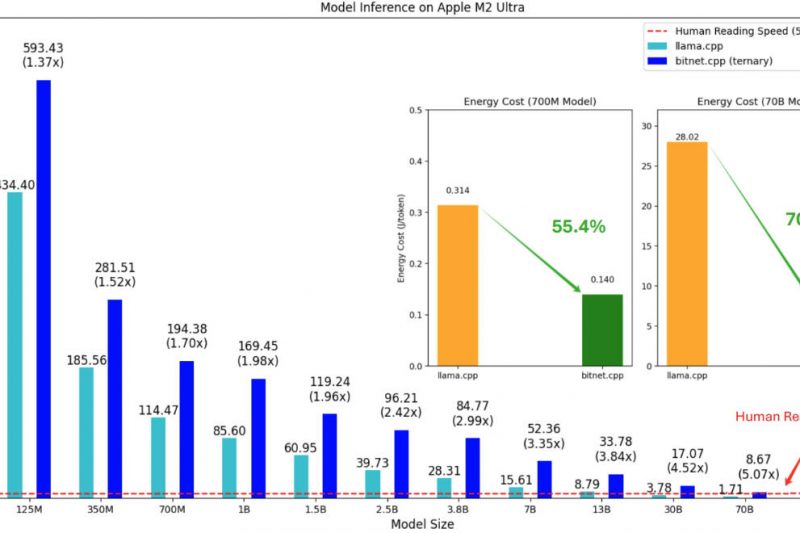
Running large language models (LLMs) used to require powerful GPUs, expensive cloud infrastructure, or specialized hardware—until BitNet changed the game.…