Deploying large language models (LLMs) in real-world applications remains a major engineering challenge. While models like LLaMA-2, Falcon, and Mixtral…
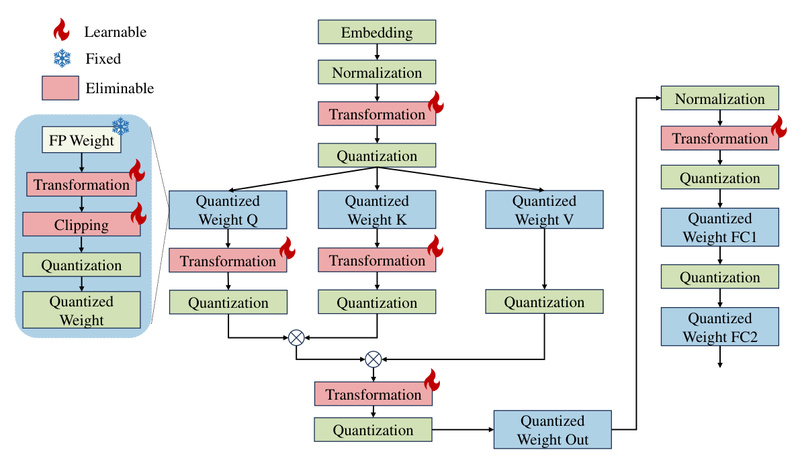
Deploying large language models (LLMs) in real-world applications remains a major engineering challenge. While models like LLaMA-2, Falcon, and Mixtral…
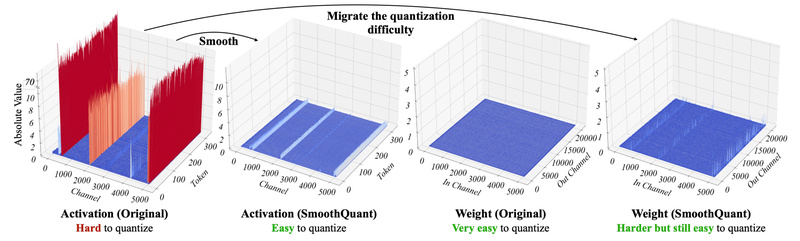
Deploying large language models (LLMs) in production is expensive—not just in dollars, but in compute and memory. While models like…