Imagine a single AI model that natively understands and generates responses across text, images, audio, and video—all in real time,…
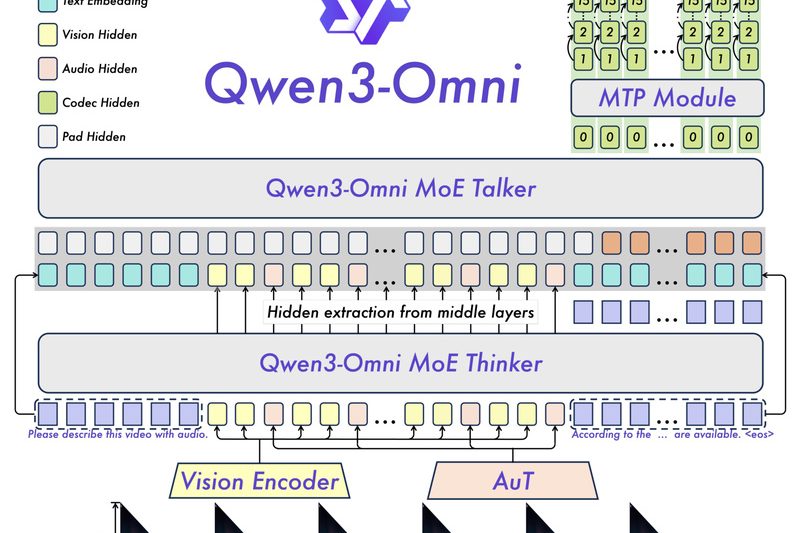
Imagine a single AI model that natively understands and generates responses across text, images, audio, and video—all in real time,…