Imagine being able to improve a large language model’s (LLM) reasoning capabilities after deployment, using only unlabeled test data—no ground-truth…
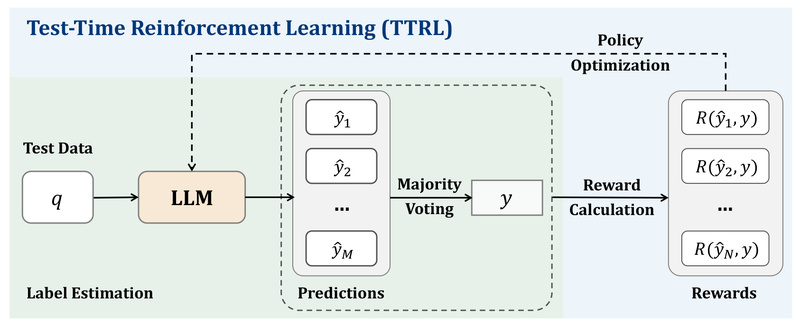
Imagine being able to improve a large language model’s (LLM) reasoning capabilities after deployment, using only unlabeled test data—no ground-truth…
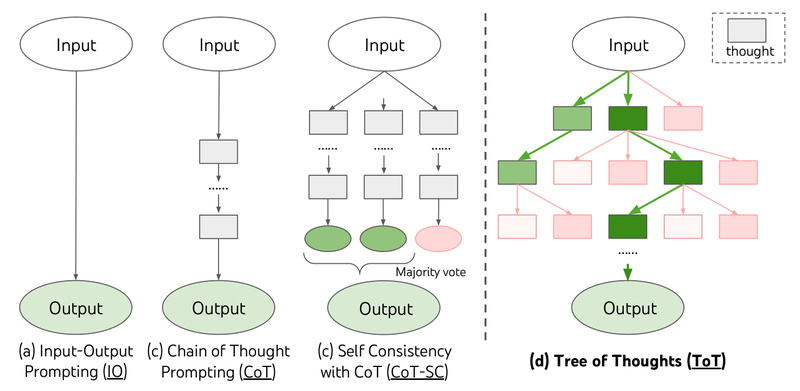
Large language models (LLMs) have transformed how we approach tasks ranging from coding assistance to content generation. Yet, their standard…
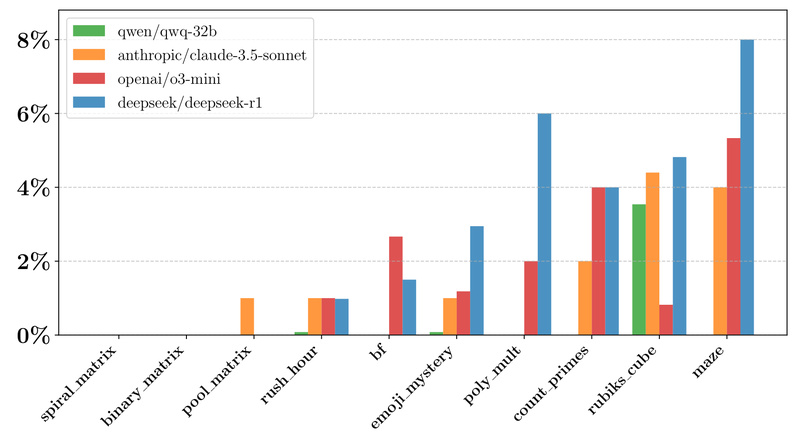
If you’re building or evaluating reasoning-capable AI systems—especially large language models (LLMs)—you’ve likely hit a wall with static benchmarks. Traditional…