Evaluating large language models (LLMs) has become increasingly challenging. Traditional benchmarks—like MMLU, GSM8K, or Big-Bench Hard—are static, fixed in complexity,…
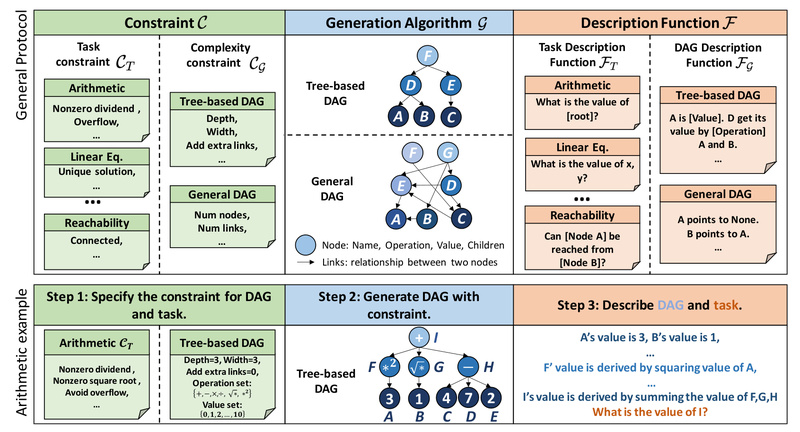
Evaluating large language models (LLMs) has become increasingly challenging. Traditional benchmarks—like MMLU, GSM8K, or Big-Bench Hard—are static, fixed in complexity,…