In the rapidly evolving landscape of large language models (LLMs), a critical limitation persists: despite their impressive fluency, LLMs often…

In the rapidly evolving landscape of large language models (LLMs), a critical limitation persists: despite their impressive fluency, LLMs often…
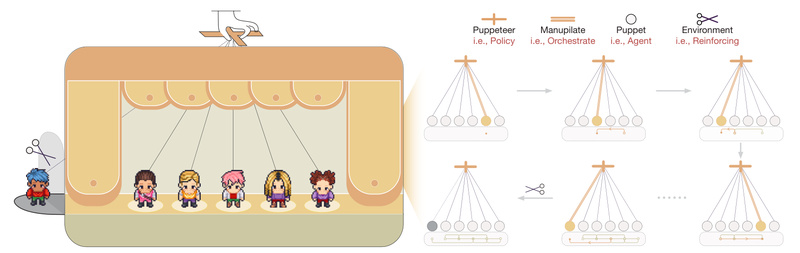
Managing complex tasks with large language models (LLMs) often hits a ceiling: while single models excel at narrow tasks, scaling…