If you’re building or fine-tuning large language models (LLMs) for reasoning—whether in math, coding, search, or agentic workflows—you’ve likely hit…
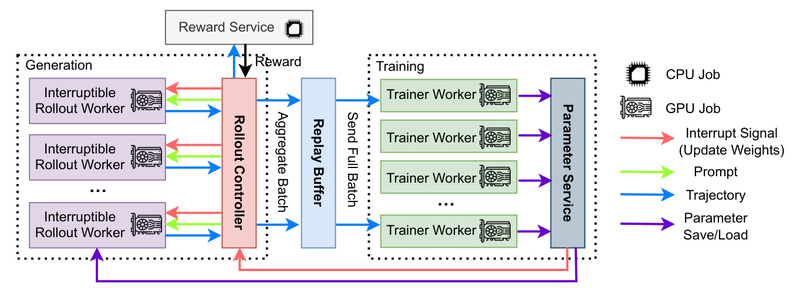
If you’re building or fine-tuning large language models (LLMs) for reasoning—whether in math, coding, search, or agentic workflows—you’ve likely hit…
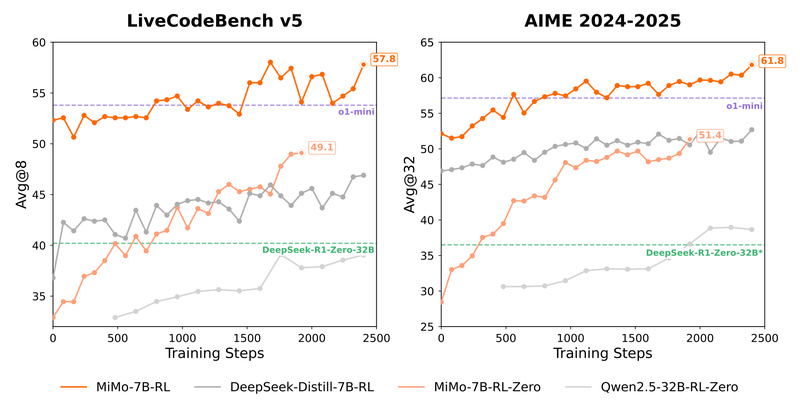
MiMo is a 7-billion-parameter language model purpose-built for reasoning-intensive tasks—spanning mathematics, code generation, and STEM problem solving—without the computational overhead…
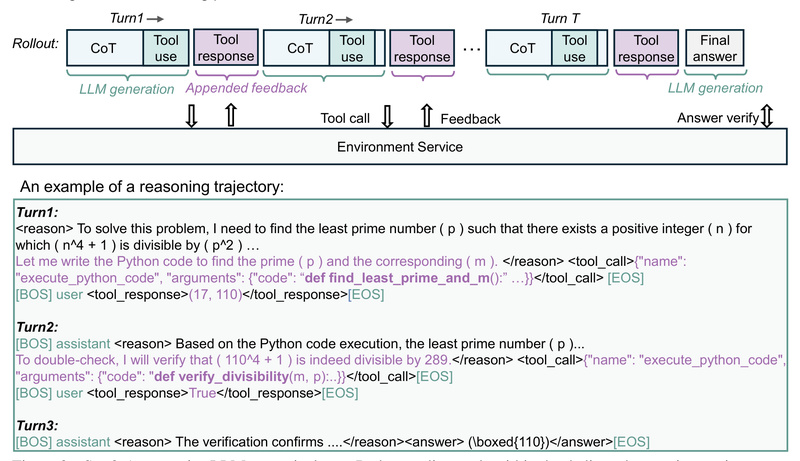
In the rapidly evolving landscape of large language models (LLMs), bigger isn’t always better—smarter is. Enter rStar2-Agent, a 14-billion-parameter reasoning…