In today’s fast-moving technical and research environments, teams need reliable, up-to-date answers to complex questions—without the black-box limitations or high…
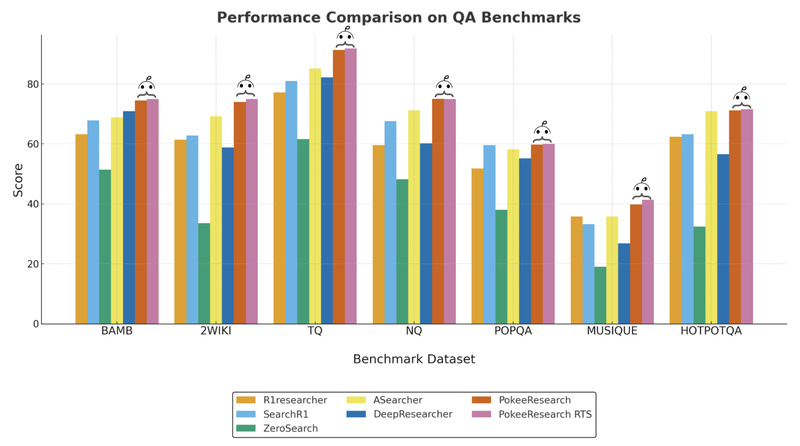
In today’s fast-moving technical and research environments, teams need reliable, up-to-date answers to complex questions—without the black-box limitations or high…