In an era where deep learning models grow ever larger and more opaque, the demand for interpretable, efficient, and theoretically…
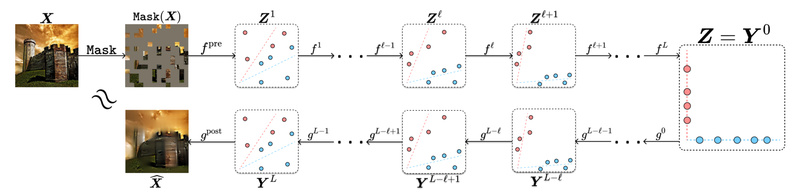
In an era where deep learning models grow ever larger and more opaque, the demand for interpretable, efficient, and theoretically…

In today’s AI landscape, building systems that understand multiple types of data—text, images, audio, video, time series, and more—is increasingly…