Imagine deploying a single robot policy that works across different hardware—robotic arms, mobile bases, or even human-inspired setups—without retraining from…
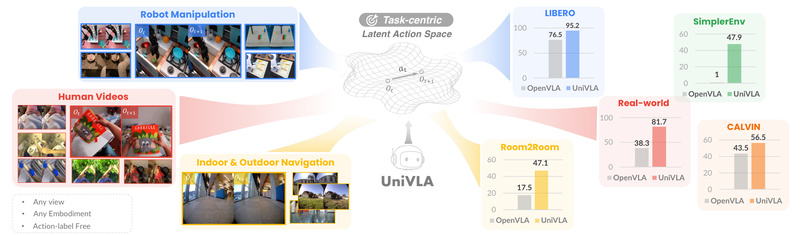
Imagine deploying a single robot policy that works across different hardware—robotic arms, mobile bases, or even human-inspired setups—without retraining from…
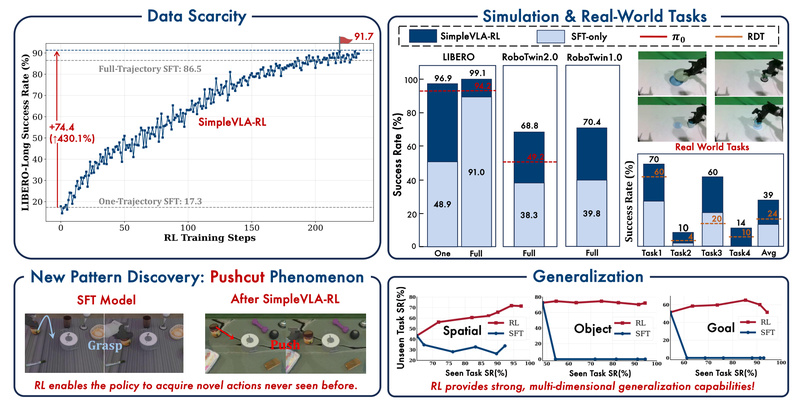
Building capable robotic systems that understand vision, language, and action—commonly referred to as Vision-Language-Action (VLA) models—has become a central goal…
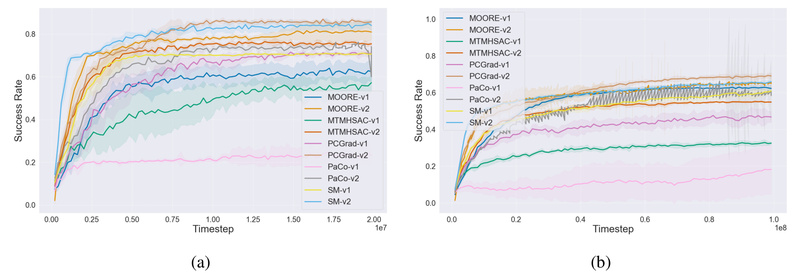
Evaluating reinforcement learning (RL) agents—especially those designed for multi-task or meta-learning scenarios—requires benchmarks that are consistent, well-documented, and technically accessible.…
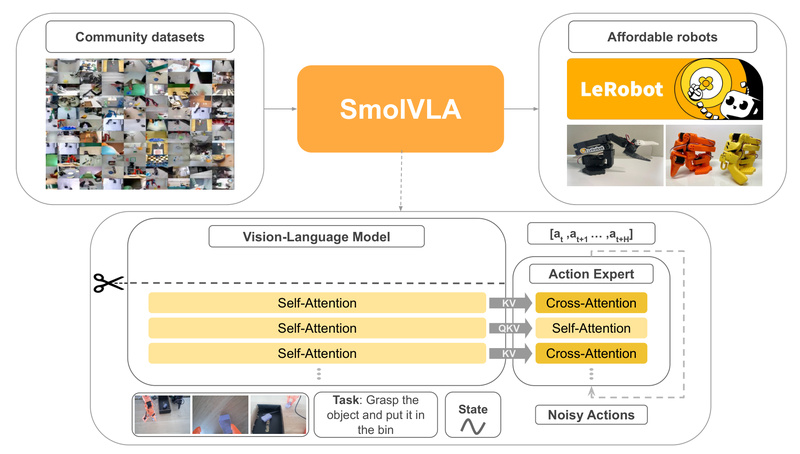
SmolVLA is a compact yet capable Vision-Language-Action (VLA) model designed to bring state-of-the-art robot control within reach of researchers, educators,…