TinyLlama is a compact yet powerful open-source language model with just 1.1 billion parameters—but trained on an impressive 3 trillion…
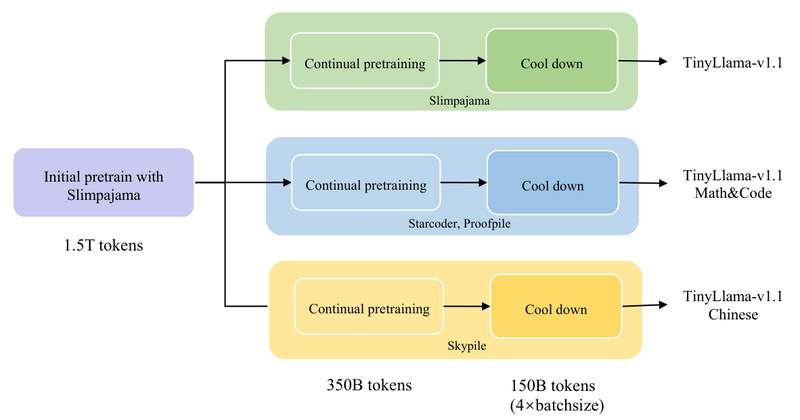
TinyLlama is a compact yet powerful open-source language model with just 1.1 billion parameters—but trained on an impressive 3 trillion…
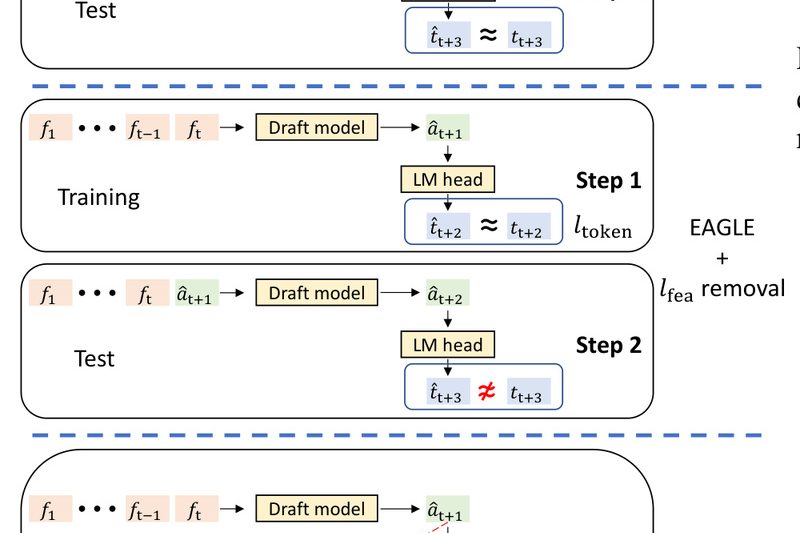
For teams deploying large language models (LLMs) in production—whether for chatbots, reasoning APIs, or batch processing—latency and inference cost are…