Evaluating large language models (LLMs) on synthetic coding benchmarks often fails to reflect their real-world utility. Enter SWE-Lancer—a rigorously constructed…
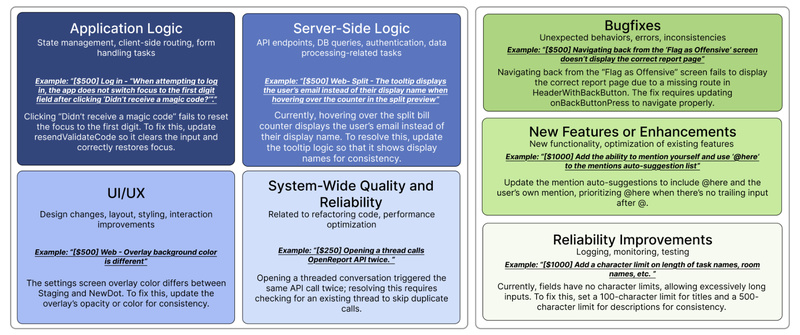
Evaluating large language models (LLMs) on synthetic coding benchmarks often fails to reflect their real-world utility. Enter SWE-Lancer—a rigorously constructed…