Generating high-quality videos from text has long been a challenging frontier in generative AI—especially compared to the rapid advances in…

Generating high-quality videos from text has long been a challenging frontier in generative AI—especially compared to the rapid advances in…
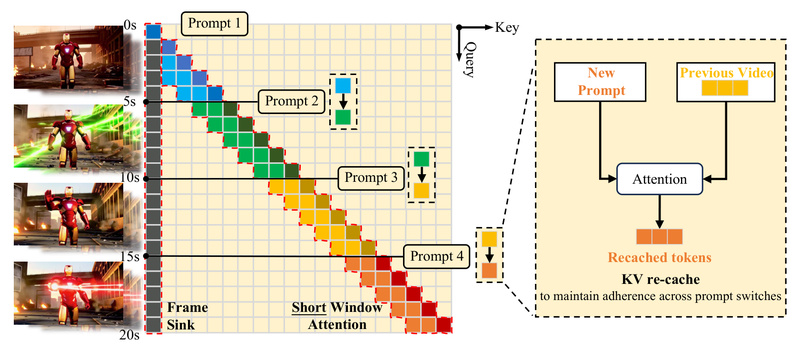
Creating long, coherent, and high-quality videos from text has long been a formidable challenge in generative AI. Existing approaches—especially diffusion-based…

In the rapidly evolving world of generative AI, video generation has remained a particularly challenging frontier—especially when it comes to…
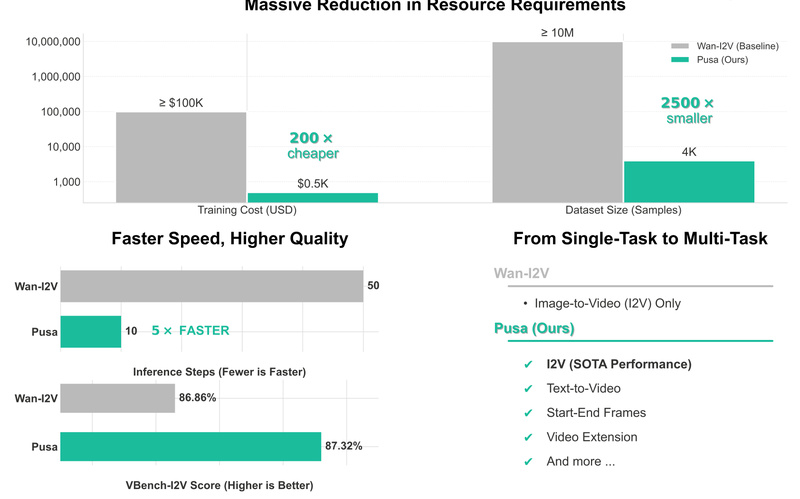
Video generation has long been bottlenecked by two stubborn realities: astronomical training costs and rigid temporal modeling. Most state-of-the-art image-to-video…

Video generation using diffusion models has long suffered from a crippling bottleneck: speed. Even the most advanced models can take…
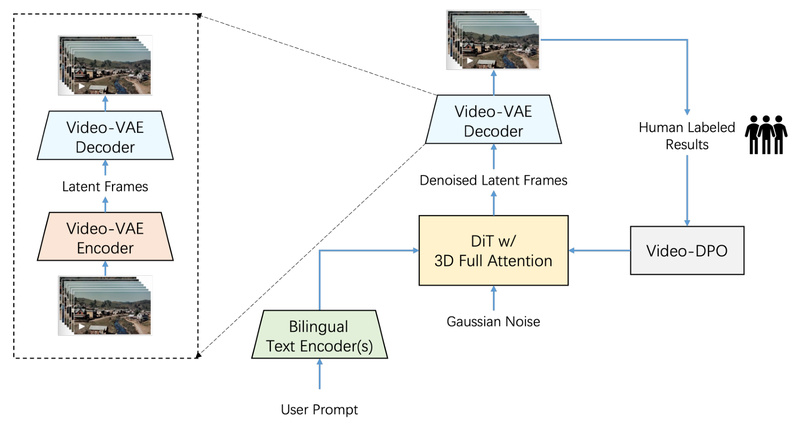
Step-Video-T2V is a state-of-the-art open-source text-to-video foundation model developed by StepFun AI. With 30 billion parameters and the ability to…
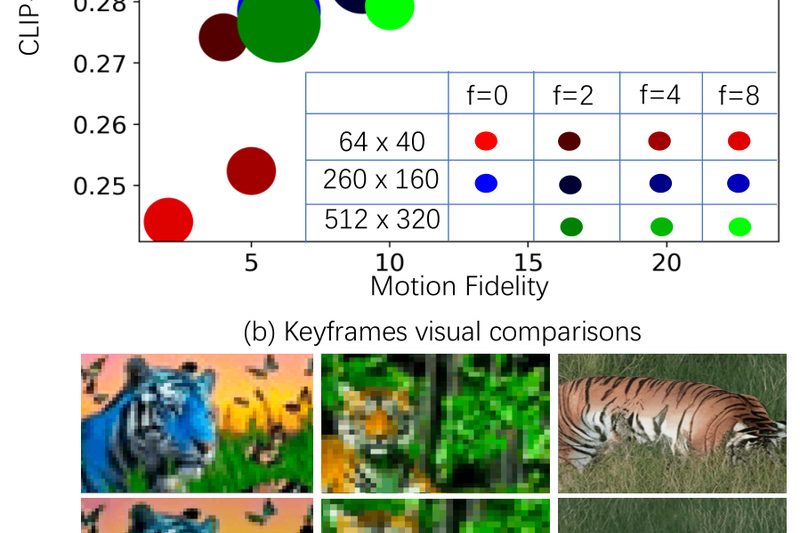
Text-to-video generation has rapidly evolved, yet technical teams still face a persistent trade-off: high-quality outputs often come at prohibitive computational…
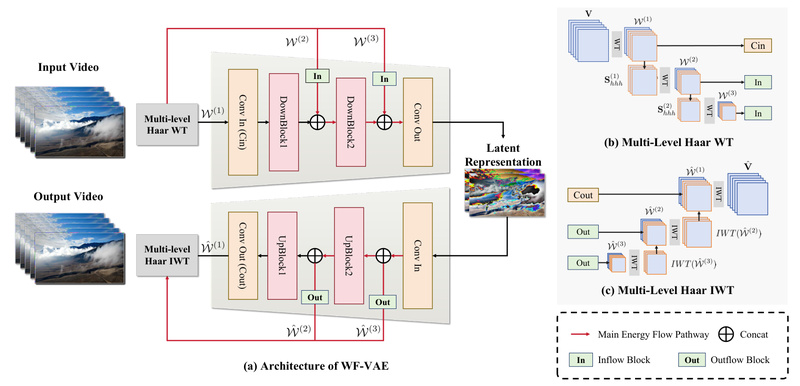
Open-Sora Plan is an open-source initiative designed to democratize access to state-of-the-art video generation capabilities. Inspired by the promise of…

Most text-to-video (T2V) models today excel at generating short clips of people walking, cars driving, or birds flying—but they struggle…

If you’ve spent time fine-tuning a Stable Diffusion model—perhaps with DreamBooth or LoRA—to generate your ideal character, product mockup, or…